
- 1.abstract
- 這篇論文介紹了一種名為 MixStyle 的簡單、無需額外參數的模組,旨在解決神經網絡面對未見數據時的泛化問題。MixStyle 的設計靈感來自於最近的風格轉換研究,該研究發現特徵統計信息(即特徵圖的通道均值和標準差)能夠捕捉到圖像的風格信息,進而定義視覺域。因此,MixStyle 通過在訓練過程中的單次前向傳播中混合兩個隨機實例的特徵統計信息,來實現在特徵空間中合成新的域,從而達到數據增強的目的。MixStyle 易於實現,只需幾行代碼即可插入到現有模型中,而且不需要修改訓練目標。這使得 MixStyle 可以輕鬆適配於包括監督域泛化、半監督域泛化和無監督域適應等多種學習範式。
- 2.background
- Instance Normalization (IN)
- Instance Normalization 最早是在風格轉換(style transfer)的上下文中提出的。它的核心思想是在每個特徵圖(feature map)上獨立地進行標準化,對每個樣本分別計算均值和標準差,然後用這些統計量對特徵進行標準化。這樣做可以有效地移除每個樣本中的風格信息,從而有助於在風格轉換任務中保留內容信息而轉換風格。
- 從 IN 到 AdaIN
- AdaIN (Adaptive Instance Normalization) 建立在 IN 的基礎上,進一步將這一概念推廣到了任意風格轉換。AdaIN 不僅移除了一個圖像(通常是內容圖像)的風格信息,還通過動態調整標準化後的特徵,將另一個圖像(風格圖像)的風格統計量(即均值和標準差)應用到這些特徵上。這樣做使得模型能夠將任意風格應用到給定的內容圖像上,從而達到任意風格轉換的效果。
- 具體來說,AdaIN 接受兩個輸入:一個是內容圖像的特徵表示,另一個是風格圖像的特徵表示。AdaIN 首先對內容特徵進行 instance normalization,然後將風格特徵的統計信息(均值和標準差)應用到標準化後的內容特徵上。這一過程可以被視為一種「風格適應」,使得轉換後的特徵既保留了內容信息,又融入了新的風格信息。
- Instance Normalization (IN)
- 3.method
- MixStyle 進一步擴展了 AdaIN 的概念,將其應用從風格轉換擴展到域泛化和適應。MixStyle 的核心思想是在訓練過程中,隨機選擇兩個實例的特徵,然後混合它們的統計信息(均值和標準差),以此方式合成新的「虛擬域」。這種特徵層面的數據增強手段能夠有效地提高模型對未見域的泛化能力。
- MixStyle 不需要額外的參數或複雜的計算,易於實現並且可以無縫集成到現有的神經網絡架構中。它的靈活性和通用性使得 MixStyle 不僅適用於圖像識別、實例檢索等任務,還可以輕鬆應用於半監督學習和無監督學習設置。
- MixStyle 也可以輕易地使用在沒有標記的Data中,因為在Mixstyle中,引進另一份資料也只是要計算mean與variance 而已,論文中也聲稱使用Unlabel Data 比沒有使用的效果還要更好
- 4.experiments
- 實驗一:在PACS數據集上的類別分類泛化
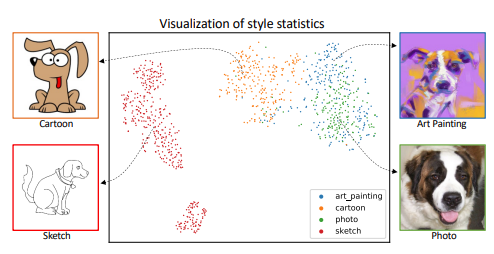
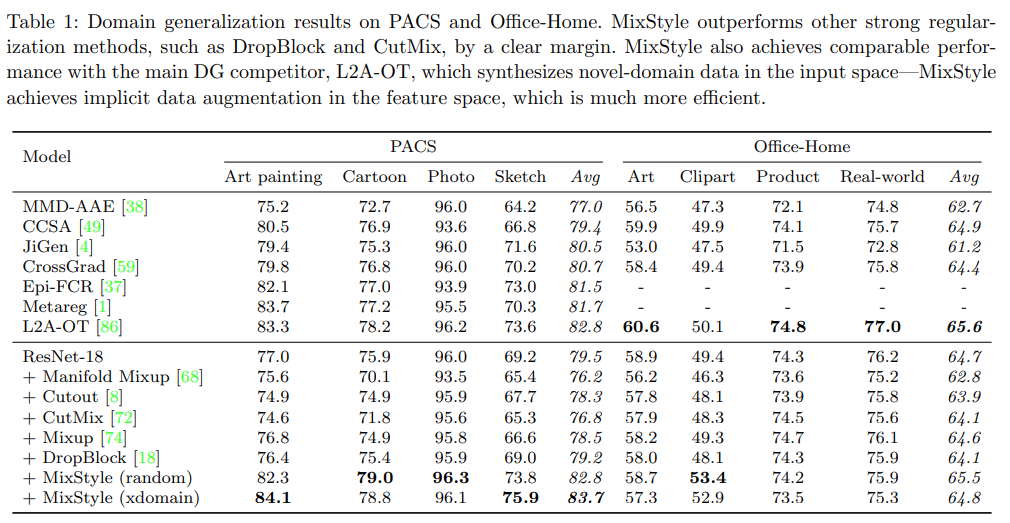
- a. 未使用MixStyle的數據:
- ResNet-18在PACS數據集上的平均準確率為79.5%。
- b. 使用MixStyle的數據提升:
- 在ResNet-18中引入MixStyle後,根據不同領域的實驗設置,準確率有所提升。具體來說,最顯著的提升出現在“Art”和“Sketch”領域,分別達到了82.3%±0.2%和73.8%±0.9%,而平均準確率提升至82.8%。此外,使用領域標籤的MixStyle進一步提升了性能,平均準確率達到了83.7%。
- 實驗二:跨數據集人員重新識別任務上的泛化
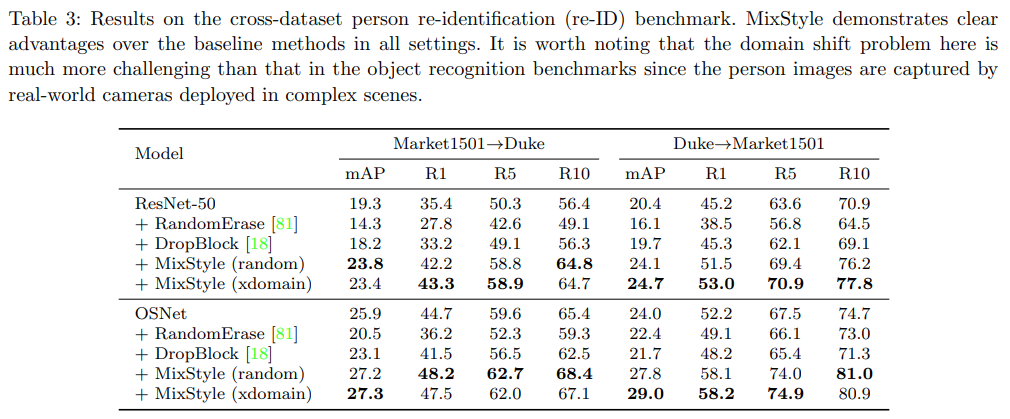
- ResNet-50和OSNet模型在使用MixStyle後,在Market1501⇒Duke和Duke⇒Market1501的跨數據集設置中展示了一致的性能提升。具體來說,在Market1501⇒Duke設置中,ResNet-50配合MixStyle的最高mAP分數分別為23.8%(隨機洗牌)和23.4%(使用領域標籤),在Duke⇒Market1501設置中,這些分數分別為24.1%和24.7%。這顯示了MixStyle在提升人員重新識別模型在未見過攝像頭視角下的泛化能力方面的有效性。
- 實驗三:強化學習中的泛化
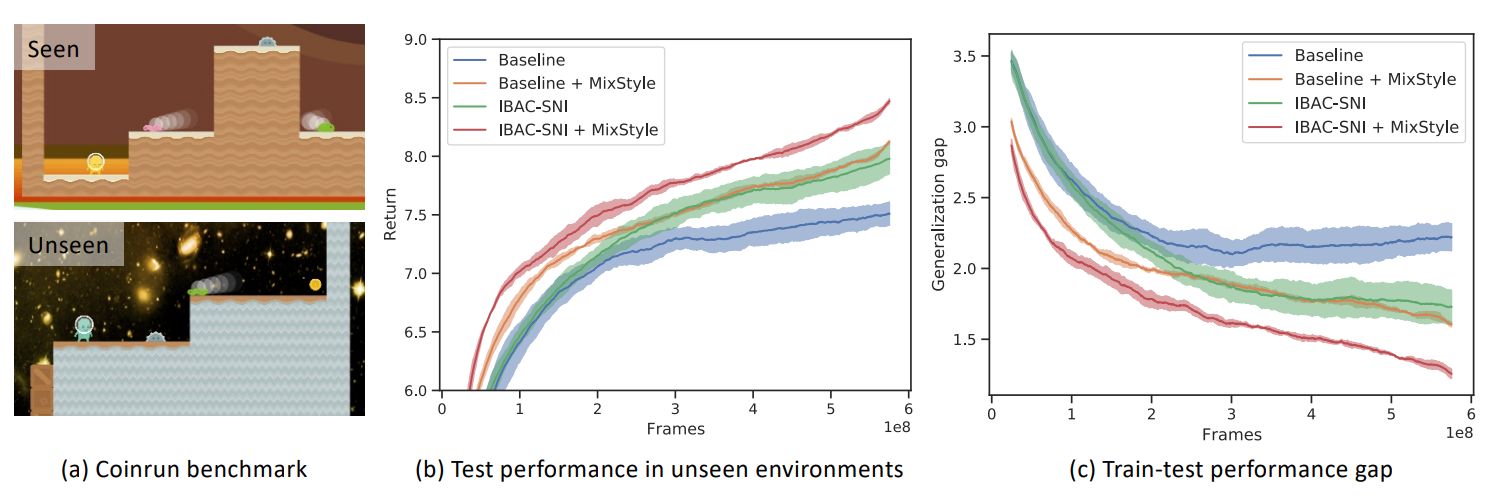
- 未使用MixStyle:
- 實驗中沒有直接提到未使用MixStyle的基線模型在Coinrun強化學習任務中的具體表現。然而,可以假設基線模型的性能較低,這是因為強化學習模型通常在面對未見過的環境時泛化能力較差。
- 使用MixStyle:
- 在Coinrun任務中,使用MixStyle後,模型顯示出顯著的性能提升。這表明MixStyle能有效地增強強化學習模型在未見過的環境中的泛化能力,儘管文檔中沒有提供具體的性能提升數字。
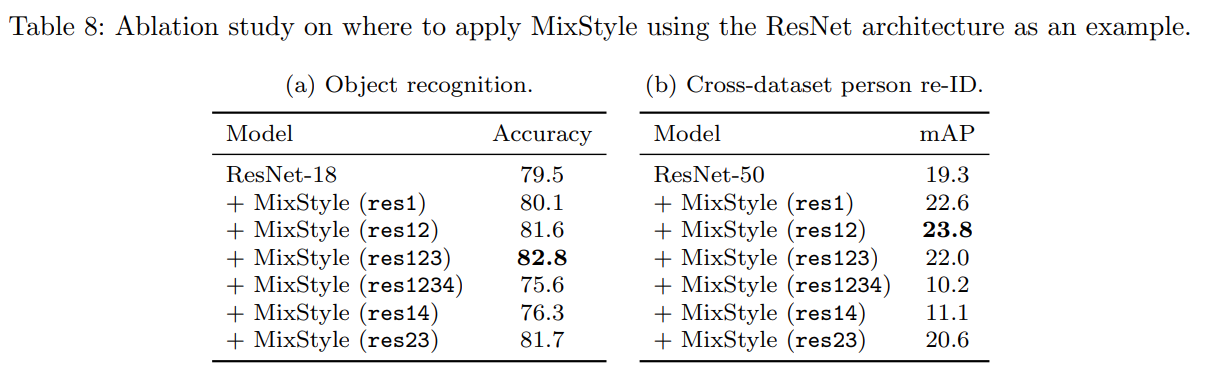
- 實驗四:不同插入層次的MixStyle效果
- 未使用MixStyle:
- 類似於前面的實驗設置,未使用MixStyle的基線模型在所有任務中提供了性能的參考點。
- 使用MixStyle:
- 當MixStyle應用於ResNet架構的不同層時,實驗結果顯示在底層和中層插入MixStyle能獲得最佳效果。具體來說,在PACS數據集上,將MixStyle應用於第一、第二和第三殘差塊之後(res123),平均準確率可達到82.8%,而在所有四個殘差塊之後應用(res1234)則會導致性能下降,平均準確率僅為75.6%。
- 實驗五:MixStyle參數的敏感性分析
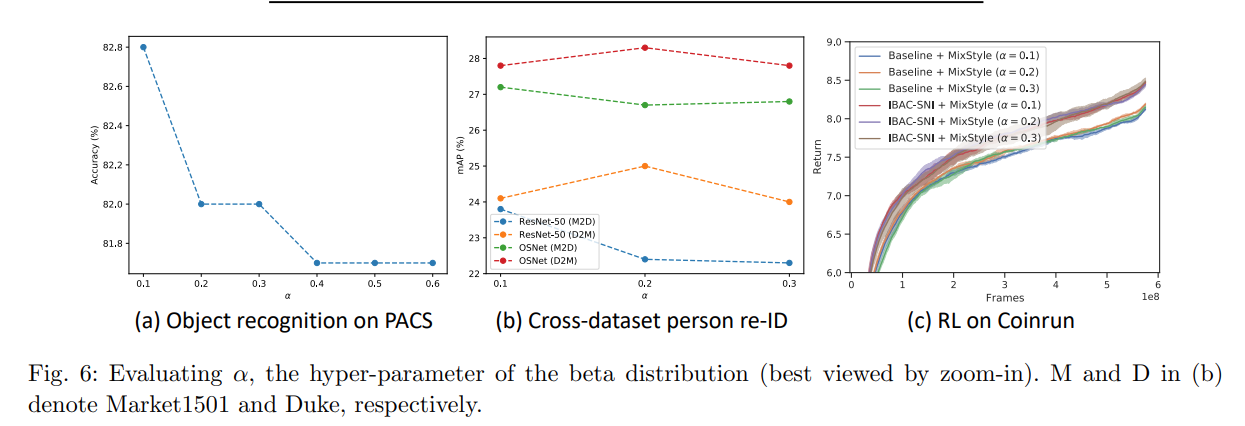
- 實驗中探討了MixStyle中Beta分佈參數α的影響。結果表明,α的不同值對模型性能有輕微影響,但整體上MixStyle不太敏感於α的變化。選擇α值為0.1、0.2或0.3時,模型能夠保持穩定的性能。
- 實驗六: 不同的generalization 方法比較
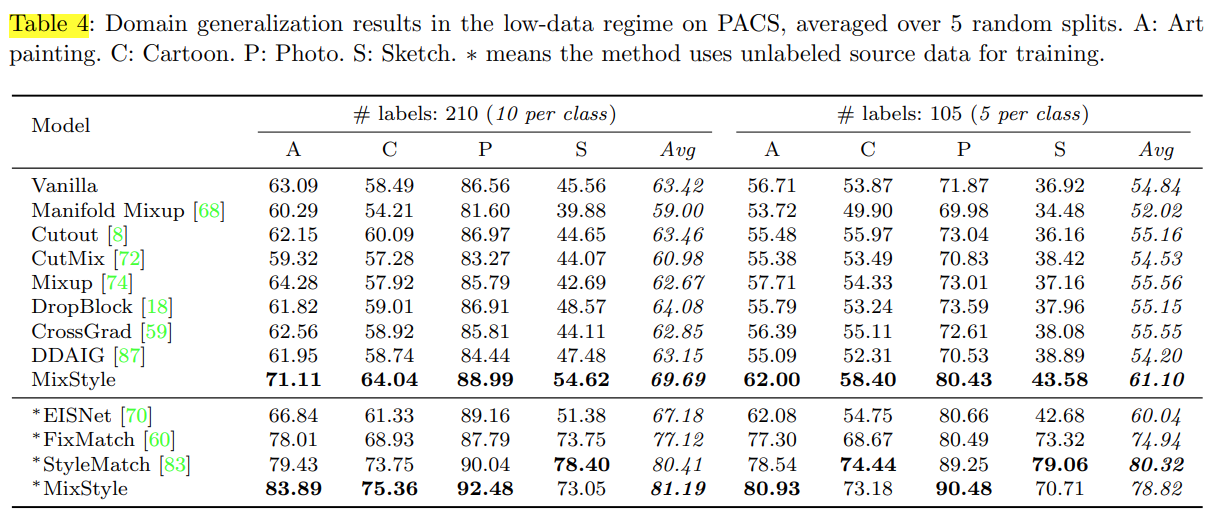
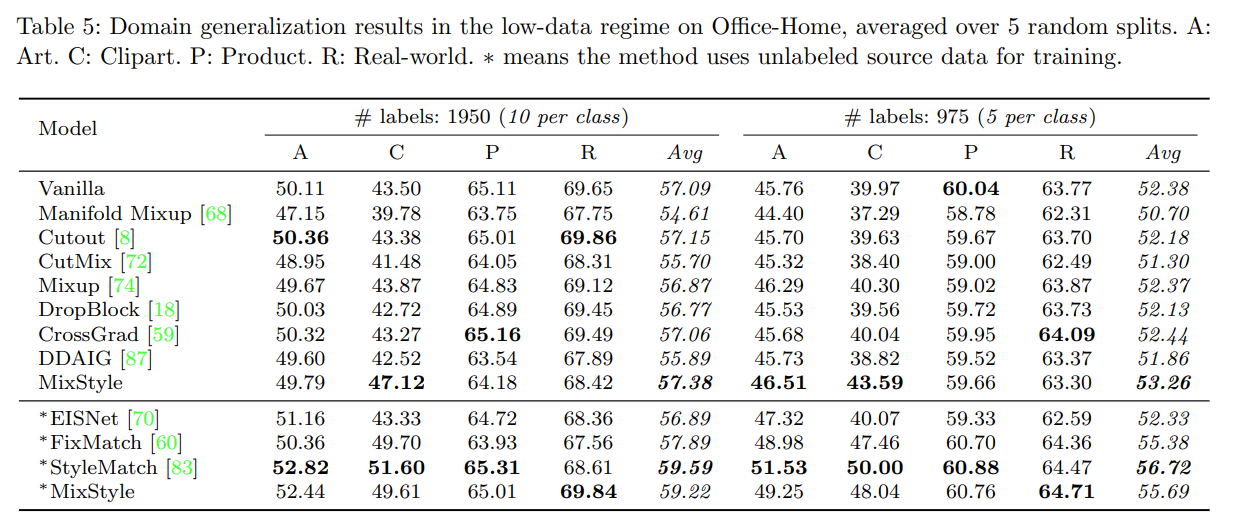
- 由圖表可以得知Mixstyle 和其他方法相比較起來只輸了stylematch 一點點而已,其中*代表使用沒有label的資料進行訓練,由表中也可以得知mixstyle對於SSDG(semi-supervised domain adaptation)任務也表現良好,原本沒有使用unlabel data 的平均準確度為62.69,有使用unlabel data後平均準確度提升到了81.19,著實提升效果非常多
- 實驗一:在PACS數據集上的類別分類泛化
- 5.code
- 核心程式碼如下所示,有兩種模式,一種為ramdom的模式,將資料x輸入後再把所有資料的順序都打亂產生x’,而另一種模式為cross domain 模式,把
- 程式碼來自原文作者: mixstyle-release/reid/models/mixstyle.py at master · KaiyangZhou/mixstyle-release
def forward(self, x):
# MixStyle is disabled during testing phase
if not self.training or not self._activated:
return x
if random.random() > self.p:
return x
B = x.size(0)
mu = x.mean(dim=[2, 3], keepdim=True)
var = x.var(dim=[2, 3], keepdim=True)
sig = (var + self.eps).sqrt()
mu, sig = mu.detach(), sig.detach()
x_normed = (x-mu) / sig
lmda = self.beta.sample((B, 1, 1, 1))
lmda = lmda.to(x.device)
if self.mix == "random":
# random shuffle
perm = torch.randperm(B)
elif self.mix == "crossdomain":
# split into two halves and swap the order
perm = torch.arange(B - 1, -1, -1) # inverse index
perm_b, perm_a = perm.chunk(2)
perm_b = perm_b[torch.randperm(perm_b.shape[0])]
perm_a = perm_a[torch.randperm(perm_a.shape[0])]
perm = torch.cat([perm_b, perm_a], 0)
else:
raise NotImplementedError
mu2, sig2 = mu[perm], sig[perm]
mu_mix = mu*lmda + mu2 * (1-lmda)
sig_mix = sig*lmda + sig2 * (1-lmda)
return x_normed*sig_mix + mu_mix
參考資料