

Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices (ECB)
內容目錄
1.abstract
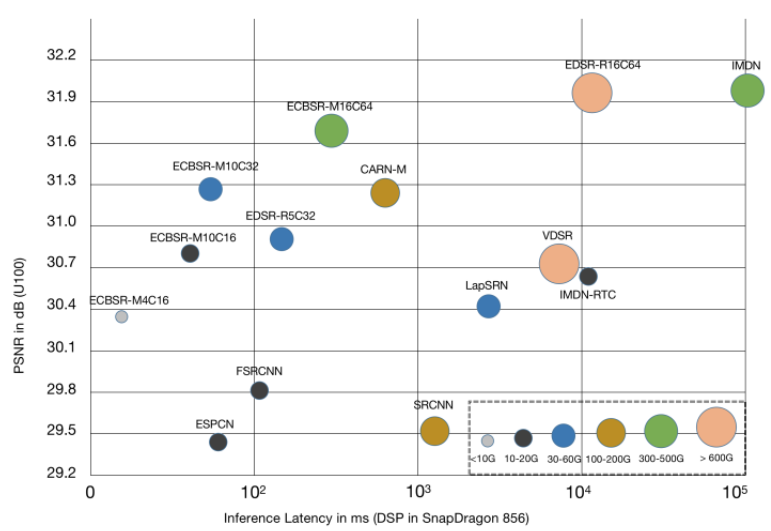
本文提出了一個針對高效超分辨率(SR)設計的可重參數化建構塊,名為邊緣導向卷積塊(ECB)。大多數現有研究致力於減少模型參數和FLOPs,但這可能並不一定在移動設備上提高運行速度。ECB通過多路徑提取特徵,包括普通的3×3卷積、通道擴展和壓縮卷積,以及從中間特徵中提取的一階和二階空間導數。在推理階段,這些多個操作可以合併成單個3×3卷積。
2.method
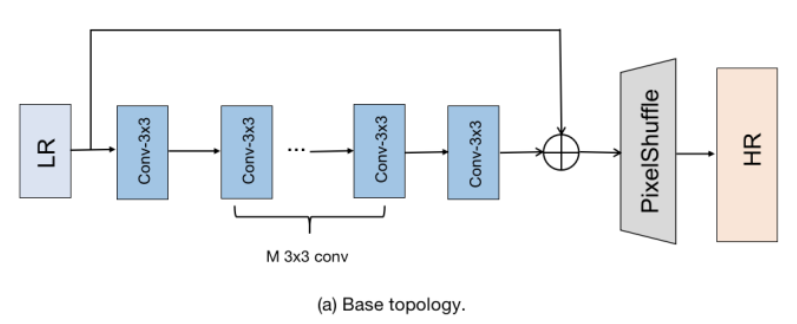
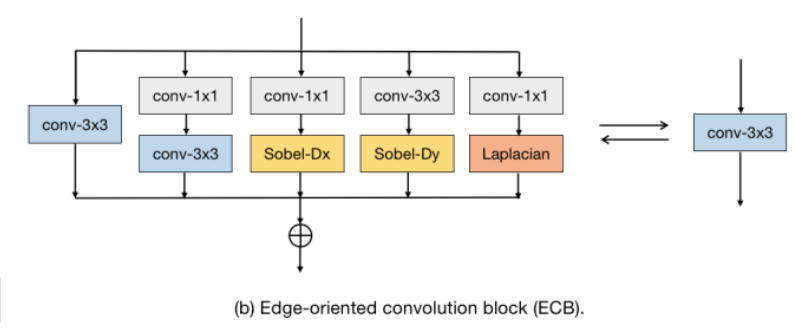
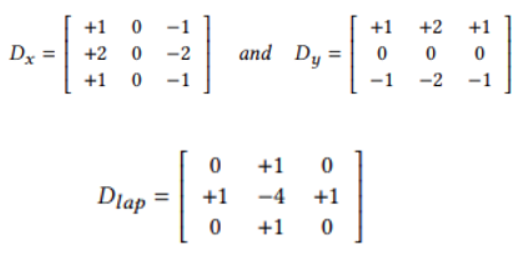
作者為了改善超解算法的性能,提出了一個名為邊緣導向卷積塊(ECB)的重新參數化塊。與先前直接應用的重新參數化塊相比,ECB更能有效地提取SR任務所需的邊緣和紋理信息,從而提高了基本模型的性能。本文的基礎技術來自於[1],描述如何把1X1卷積層 與 3X3 卷積層的串聯連接簡化成一個單純只有一個卷積核為3的卷積層
基礎並聯卷積融合技術理解 下圖為一個普通的1X1卷積層圖視流程圖
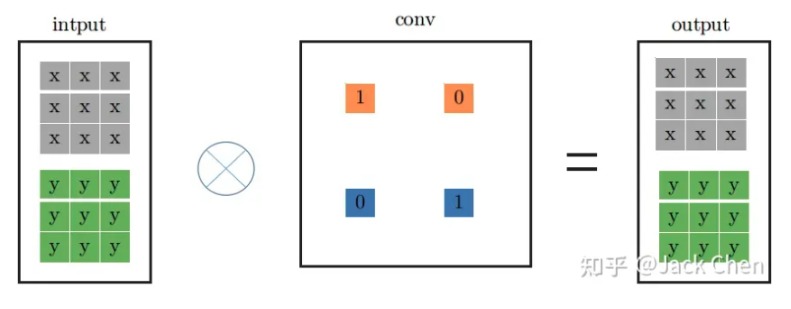 然而上述的流程操作也可以等效成下圖的3X3卷積核操作,作法只要簡單的在數字的周圍補上0即可,經過一番改動後,原本的1X1 卷積核就可以轉化為3X3卷積核了
然而上述的流程操作也可以等效成下圖的3X3卷積核操作,作法只要簡單的在數字的周圍補上0即可,經過一番改動後,原本的1X1 卷積核就可以轉化為3X3卷積核了 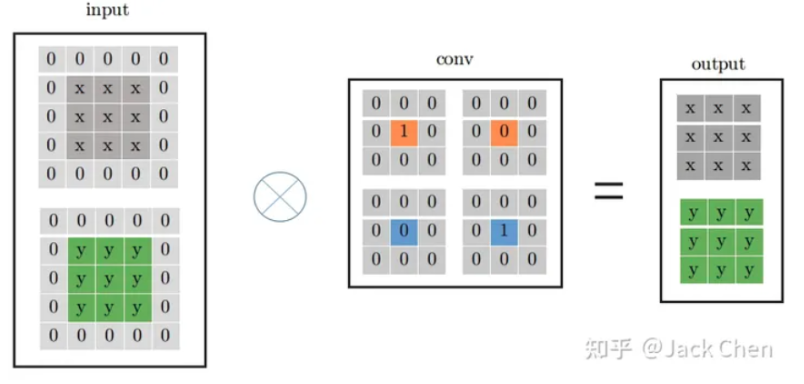 兩個並聯的卷積核可以依照下列公式推導出等效的卷積核權重 假設第一欄3X3的卷積核權重為
兩個並聯的卷積核可以依照下列公式推導出等效的卷積核權重 假設第一欄3X3的卷積核權重為  ,第二欄3X3的卷積核權重
,第二欄3X3的卷積核權重 ,輸入為X,根據流程可以推導出輸出結果如下
,輸入為X,根據流程可以推導出輸出結果如下\(O=(X*k_0+b_0)+(X*k_1+b_1)=(k_0+k_1)X+(b_0+b_1) \)
如此已經可以得出新的卷積核權重
\(k_{new}=k_0+k_1 \)
\(b_{new}=b_0+b_1 \)
 –
– - 然而此篇論文所使用的連接方式為串聯,因此公式推導為
- \(O=(X*k_0+b_0)*k_1+b_1=k_0k_1X+b_0k_1+b_1\)
- 如此可以得出新的卷積核權重
- \(k_{new}=k_0k_1\)
- \(b_{new}=b_0k_1+b_1\)
- 完整的程式碼可以參考官方發布原始碼,部分擷取如下
# conv1X1: self.k0,self.b0
# conv3X3: self.k1,self.b1
if self.type == 'conv1x1-conv3x3':
# re-param conv kernel
RK = F.conv2d(input=self.k1, weight=self.k0.permute(1, 0, 2, 3))
# re-param conv bias
RB = torch.ones(1, self.mid_planes, 3, 3, device=device) * self.b0.view(1, -1, 1, 1)
RB = F.conv2d(input=RB, weight=self.k1).view(-1,) + self.b1
而我自己也寫了一份驗證程式來證明兩者確實是可以等效的,參考如下
import torch
import torch.nn as nn
import torch.nn.functional as F
class TestConv:
def __init__(self):
self.type = 'conv1x1-conv3x3'
self.mid_planes = 16 # Example value
self.k0 = torch.randn(self.mid_planes, 3, 1, 1)
self.b0 = torch.randn(self.mid_planes)
self.k1 = torch.randn(self.mid_planes, self.mid_planes, 3, 3)
self.b1 = torch.randn(self.mid_planes)
def reparameterize(self, device):
# Re-param conv kernel
RK = F.conv2d(input=self.k1, weight=self.k0.permute(1, 0, 2, 3))
# Re-param conv bias
RB = torch.ones(1, self.mid_planes, 3, 3, device=device) * self.b0.view(1, -1, 1, 1)
RB = F.conv2d(input=RB, weight=self.k1).view(-1,) + self.b1
return RK, RB
# Random input
input_tensor = torch.randn(1, 3, 8, 8)
test_conv = TestConv()
# Regular 1x1 and 3x3 convolutions
conv1x1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=1)
conv3x3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3)
conv1x1.weight.data = test_conv.k0
conv1x1.bias.data = test_conv.b0
conv3x3.weight.data = test_conv.k1
conv3x3.bias.data = test_conv.b1
output_regular = conv3x3(conv1x1(input_tensor))
# Reparameterized convolution
RK, RB = test_conv.reparameterize(input_tensor.device)
conv_reparam = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
conv_reparam.weight.data = RK
conv_reparam.bias.data = RB
output_reparam = conv_reparam(input_tensor)
# Check if the outputs are close
assert torch.allclose(output_regular, output_reparam, atol=1e-5), "The outputs are not close!"
print("Test passed!")
3.experiments result
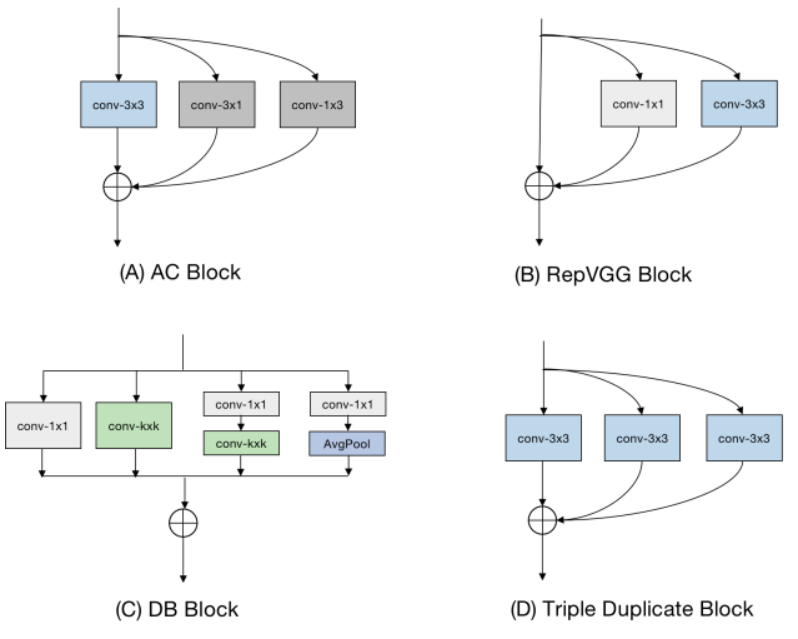
作者分別與其它不同的重參數模型相比較,可以看到作者所開發出的ECB在公眾的五個資料集達到最好的效果,作者一個一個的比較每個小方塊對實驗所造成的差異,由實驗表可以得知全部加上的效果是最好的
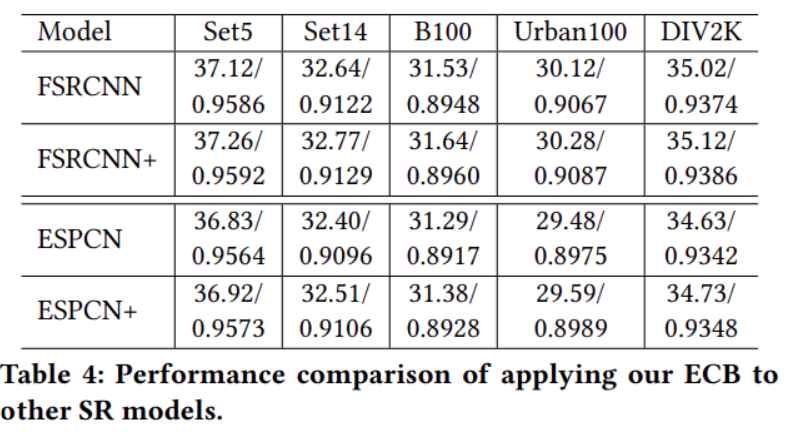
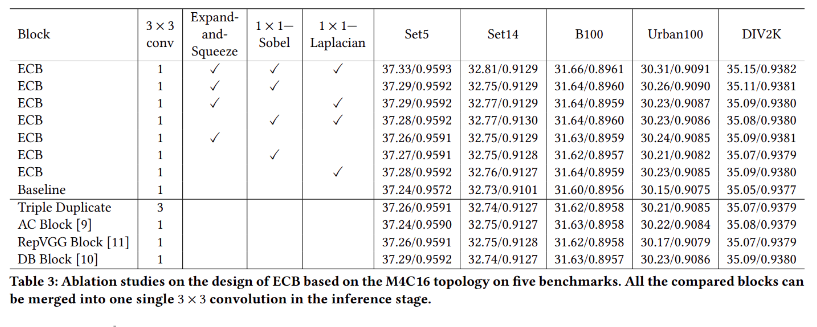 本網路架構作者也將之套用在一些SR model上,以+表示有加上ECB的模型實驗,由實驗結果圖來看可以發現兩個模型在改為ECB的架構後在公眾的五個資料集皆有提升的效果,說明此架構確實能使網路的效能更為提升且不會增加任何的參數量與計算量
本網路架構作者也將之套用在一些SR model上,以+表示有加上ECB的模型實驗,由實驗結果圖來看可以發現兩個模型在改為ECB的架構後在公眾的五個資料集皆有提升的效果,說明此架構確實能使網路的效能更為提升且不會增加任何的參數量與計算量
 下圖是各個模型的可視化比較
下圖是各個模型的可視化比較

4.reference
- Diverse Branch Block: Building a Convolution as an Inception-like Unit
- https://zhuanlan.zhihu.com/p/353697121
- RepVGG: Making VGG-style ConvNets Great Again

Nice work,bro.