
本教學將教你如何改寫網路
使它可以當成deploy層 讓你取出數據
以下教學皆翻譯來自官網:
https://github.com/BVLC/caffe/wiki/Using-a-Trained-Network:-Deploy
這裡我們以autoencoder 作為例子
首先介紹 autoencoder 整個網路訓練架構:
name: “MNISTAutoencoder”
***************************************************************訓練層
layer {
name: “data”
type: “Data”
top: “data”
include {
phase: TRAIN
}
transform_param {
scale: 0.0039215684
}
data_param {
source: “examples/mnist/mnist_train_lmdb”
batch_size: 100
backend: LMDB
}
}
***************************************************************測試層:test-on-train
layer {
name: “data”
type: “Data”
top: “data”
include {
phase: TEST
stage: “test-on-train”
}
transform_param {
scale: 0.0039215684
}
data_param {
source: “examples/mnist/mnist_train1_lmdb”
batch_size: 100
backend: LMDB
}
}
***************************************************************測試層:test-on-test
layer {
name: “data”
type: “Data”
top: “data”
include {
phase: TEST
stage: “test-on-test”
}
transform_param {
scale: 0.0039215684
}
data_param {
source: “examples/mnist/mnist_test_lmdb”
batch_size: 100
backend: LMDB
}
}
***************************************************************攤平資料
layer {
name: “flatdata”
type: “Flatten”
bottom: “data”
top: “flatdata”
}
**********************************************從資料層到第一層encoder output:1000
layer {
name: “encode1”
type: “InnerProduct”
bottom: “data”
top: “encode1”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從encoder1–>encoder1neuron
layer {
name: “encode1neuron”
type: “Sigmoid”
bottom: “encode1”
top: “encode1neuron”
}
**********************************************從encoder1neuron–>encoder2 output:500
layer {
name: “encode2”
type: “InnerProduct”
bottom: “encode1neuron”
top: “encode2”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 500
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從encoder2–>encoder2neuron
layer {
name: “encode2neuron”
type: “Sigmoid”
bottom: “encode2”
top: “encode2neuron”
}
**********************************************從encoder2neuron–>encoder3 output:250
layer {
name: “encode3”
type: “InnerProduct”
bottom: “encode2neuron”
top: “encode3”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 250
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從encoder3–>encoder3neuron
layer {
name: “encode3neuron”
type: “Sigmoid”
bottom: “encode3”
top: “encode3neuron”
}
**********************************************從encoder3neuron–>encoder4 output:30
layer {
name: “encode4”
type: “InnerProduct”
bottom: “encode3neuron”
top: “encode4”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 30
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
************************************************************************************reverse
***************************************************************從encode4–>decode4
layer {
name: “decode4”
type: “InnerProduct”
bottom: “encode4”
top: “decode4”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 250
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從decode4–>decoder4neuron
layer {
name: “decode4neuron”
type: “Sigmoid”
bottom: “decode4”
top: “decode4neuron”
}
***************************************************************從decoder4neuron–>decoder3
layer {
name: “decode3”
type: “InnerProduct”
bottom: “decode4neuron”
top: “decode3”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 500
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從decode3–>decoder3neuron
layer {
name: “decode3neuron”
type: “Sigmoid”
bottom: “decode3”
top: “decode3neuron”
}
***************************************************************從decoder3neuron–>decoder2
layer {
name: “decode2”
type: “InnerProduct”
bottom: “decode3neuron”
top: “decode2”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************從decoder2–>decoder2neuron
layer {
name: “decode2neuron”
type: “Sigmoid”
bottom: “decode2”
top: “decode2neuron”
}
***************************************************************從decoder2neuron–>decoder1
layer {
name: “decode1”
type: “InnerProduct”
bottom: “decode2neuron”
top: “decode1”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 784
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************
layer {
name: “loss”
type: “SigmoidCrossEntropyLoss”
bottom: “decode1“
bottom: “flatdata”
top: “cross_entropy_loss”
loss_weight: 1
}
***************************************************************從decoder1–>decoder1neuron
layer {
name: “decode1neuron”
type: “Sigmoid”
bottom: “decode1”
top: “decode1neuron”
}
***************************************************************
layer {
name: “loss”
type: “EuclideanLoss”
bottom: “decode1neuron“
bottom: “flatdata”
top: “l2_error”
loss_weight: 0
}
***************************************************************end
下面說明如何將上面的訓練網路改寫成deploy 層
第一步: 移除所有data 層
第二步: 移除所有與data 層 的相關層
第三步: 建造 input 層
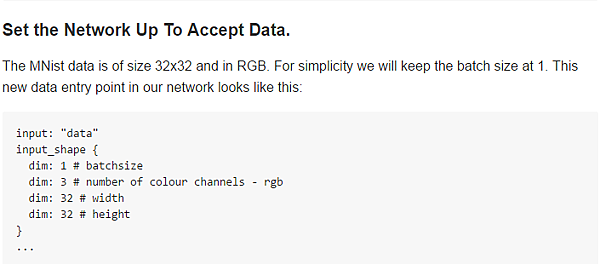
由於我們只需要encode後的資訊
decode只是訓練時需要
所以完整網路如下:
name: “MNISTAutoencoder_half”
***************************************************************
layer {
name: “data”
type: “Input”
top: “data”
input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
***************************************************************
layer {
name: “encode1”
type: “InnerProduct”
bottom: “data”
top: “encode1”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************
layer {
name: “encode1neuron”
type: “Sigmoid”
bottom: “encode1”
top: “encode1neuron”
}
***************************************************************
layer {
name: “encode2”
type: “InnerProduct”
bottom: “encode1neuron”
top: “encode2”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 500
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************
layer {
name: “encode2neuron”
type: “Sigmoid”
bottom: “encode2”
top: “encode2neuron”
}
***************************************************************
layer {
name: “encode3”
type: “InnerProduct”
bottom: “encode2neuron”
top: “encode3”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 250
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************
layer {
name: “encode3neuron”
type: “Sigmoid”
bottom: “encode3”
top: “encode3neuron”
}
***************************************************************
layer {
name: “encode4”
type: “InnerProduct”
bottom: “encode3neuron”
top: “encode4”
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 1
decay_mult: 0
}
inner_product_param {
num_output: 30
weight_filler {
type: “gaussian”
std: 1
sparse: 15
}
bias_filler {
type: “constant”
value: 0
}
}
}
***************************************************************必須再另外加上這層
layer {
name: “encode4neuron”
type: “Sigmoid”
bottom: “encode4”
top: “encode4neuron”
}
想詢問如果想將fc層的輸出結果拿來做autoencoder昰行的通的嗎
版主回覆:(08/14/2018 08:19:38 PM)
可以阿,你可以一直接
接到最後只剩下兩顆神經元
我就做過MNIST的實驗
把那兩顆當成 座標X Y軸會發現圖形很漂亮~~^.^
但我想問一下,把FC層的特徵取出時是儲存成lmdb,然後直接用lmdb去做encoder,那這樣我要如何取出encoder層的特徵呢?
版主回覆:(08/21/2018 08:11:09 PM)
你可以把FC的 output 都記錄下來,收集很多組之後把它當成autoencoder的input 然後再去訓練,就可以訓練出encoder層的特徵了
那可以在問一下,我的Fc層輸出是relu那這樣我encoder的loss layer該用什麼方法去計算呢
版主回覆:(08/29/2018 11:39:41 PM)
不太懂你的意思? 是問說loss layer的 activation function? 還是問loss function的設計方式?