
Chap4:Dynamic Programming
講完了RL的概念後,再來就是想辦法使得V值以及Q值越大越好,這樣就代表我們可以拿到更多reward,後面的章節就是在講採用何種方法可以最大化這些值,DP 就是其中一個解決MDP的辦法,其他辦法還有Monte Carlo(Chapter 5)就是Alpha Go 採取的方法,TD(Chapter 6)等等。
相信經過前面的講解後,各位對這三行方程式應該就不再陌生了,這三行是推導DP前的重要假設:
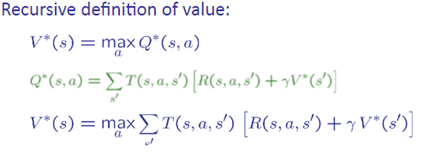

Q learning 其實是TD的一種而不是DP,但他是由DP漸漸演變而來的,因此還是會從DP開始介紹起,看完這章節必須看懂這3個名詞才叫學會這章,分別是value iteration,policy evaluation,policy iterationr。
Value iteration:
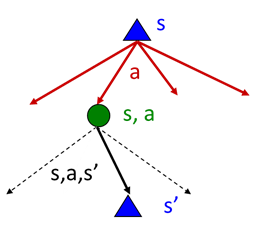



底下為實現value iteration 的演算法,環境以剛剛的地圖為例子
現在我們就來舉一個實際的MDP模型吧,總共有3個狀態cool,warm,overheated,兩種action:slow, fast,綠色的表示reward,如果把車開太快,那麼車有可能因為過熱而無法繼續開,但如果開太慢可能又無法即時到達目的地,底下就示範如何用value iteration解出這MDP模型。
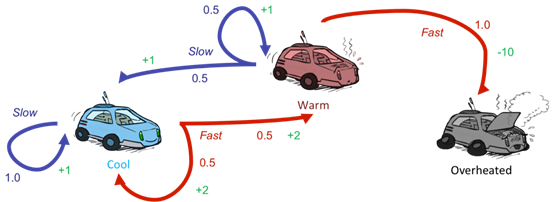


解法:
按照公式,下一個時間狀態k+1的V值等於後面那一長串,把所有的action都代進去算,選擇最大的去更新。
這裡示範一個V1(cool)的算法,假設沒有折扣率也就是γ=1:
總共有兩個action分別都算出來
1.slow: T(cool,slow,cool)*[r(cool,slow,cool)+1*v0(cool)]=1
2.fast: T(cool,fast,cool)*[r(cool,fast,cool)+1*v0(cool)]
+T(cool,fast,warm)*[r(cool,fast,warm)+1*v0(warm)]
=0.5*(2+1*0)+0.5*(2+1*0)=2
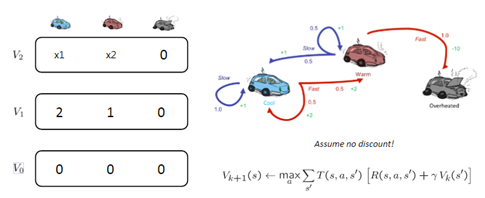
所以算出來最大action為fast,因此將v1(cool)更新為2,再來就請大家自己動手算一算 X1,X2分別為多少? (解答是 x1=3.5 x2=2.5)
真的算出來了,那恭喜你應該懂了value iteration 了
這裡建議真的要算出來再繼續往下看,不然看到後面可能會真的看不懂
根據這樣的算法一直算下去,你會發現算到Vn時,再算Vn+1,兩個的值竟然一模一樣,這時我們就會說收斂(converge)了,代表你已經找出optimal的value值了,也代表這方程式符合我們剛剛所推的Bellman equation性質
![]()

但是大家想想value iteration 有什麼缺點呢?
答:太慢了,他的時間複雜度為O(S2A),分別是當前有幾個狀態S,移轉到下一個狀態S’總數,以及action數目,等於每個都要算阿
那有什麼辦法可以簡化呢?有的,因此新的辦法policy evaluation就被想出來了,新的想法是為何我不能找其中一個action就好呢,我可以制定一個policy,然後去評斷這policy是好還是壞就好了,因此時間複雜度可以減少為O(S2)。
Policy evaluation:

![]()

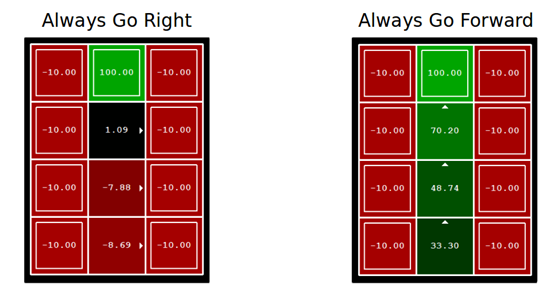
如上圖,我可以制定一個policy總是都往右走,另一個policy總是往前走,經由policy evaluation後,相信哪個policy比較好大家應該看出來了吧!
但是我知道哪一個policy比較好了,怎麼把他改成比較好的那個policy呢?policy iteration 就是在執行這個動作,先用evaluation 找出哪一個policy好,然後再改變我的policy。
Policy Iteration:


Step 1: Policy evaluation

![]()
Step 2: Policy improvement

![]()
優點:在某些情況下可以收斂的比較快
缺點::相較於TD還是太慢了