
Neural Fitted Q Iteration

想要懂DQN,讀懂NFQ [1] 是必經過程,NFQ講述的是RL和類神經結合的方法,而差別只是DQN是把類神經用深度學習的CNN取代了,由於結合深度學習因此產生出令人驚嘆的效果出來。[2] 將 NFQ這項技術用圖片環境作實驗,小編的環境和他差不多只是更簡化,在我的環境中左上角為起點,右下角為終點,到了終點拿到reward為1其餘為0。全程實驗中都以圖片的像素作為狀態輸入,因此在一張長寬各30像素的圖片中,每一個像素存在256種可能(灰階),所以總狀態共有256的900次方這麼多,用傳統的Q table方式是絕對無法解決的,因此在 [1]中作者就提出了 Replay Experience,把走過的經驗都記錄在一個tuple中,D(s,a,s’,r)然後經由Rprop batch learning的方式每次從這些經驗中撈取一些來對類神經做訓練,訓練方式為將類神經後面supervised項目改為圖中紅色的字,讓類神經取代成為以前的Qtable(s,a,w),所以在這裡類神經的輸出就是相當於那個狀態的Q值。

程式demo:
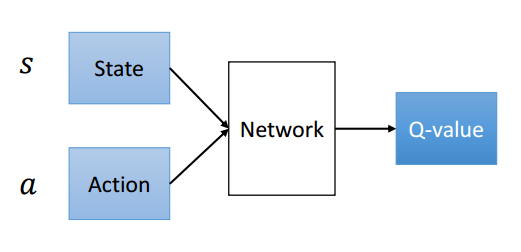
本實驗採取的架構為:
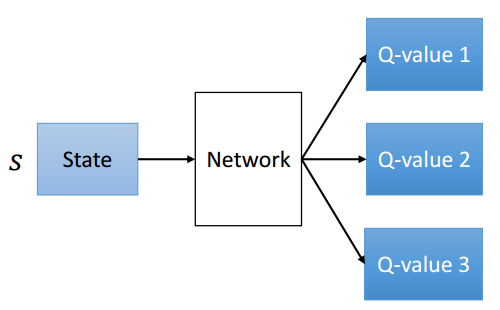
而DQN採取的架構為:
程式原始碼下載:https://github.com/darren1231/Simple-DQN
程式解說:
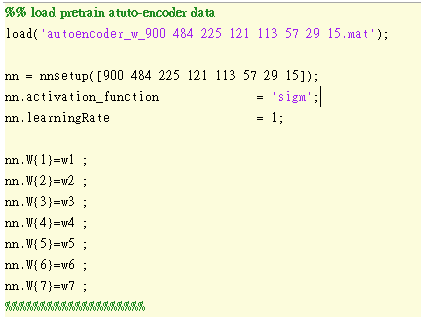
把已經訓練好的autoencoder 的參數拿進來
剛開始先去收集經驗
這是experience,前面代表每一個狀態圖像輸入autoencoder時所產生的15顆output神經元
experience(:,i)=[output’;action_table;position_x;position_y;reward];
後面表示動作狀態,

position_x;position_y 代表下一個狀態,以及最後一個存取reward,所以整段合起來就是在實現experience replay,這是DQN成功的關鍵因素之一
所以input 為
丟入一個輸入層為19,隱藏層為10,輸出層為一顆神經元的類神經模型中
開始訓練,初始化座標為左上角(1,1)
為了計算方便,我一開始就會算出最大值,並把他存在矩陣中
這是實現折扣率的關鍵,折扣率設0.9
之前存success,fail 現在就派上用場了

之後做iteration
iteration 作用為實現此一公式,重點就在於這個網路,可以用一次丟很多資料用batch learning方式學習,這裡我採用的為 R-prop 法 [3],在matlab中實現就只要將後面參數改成trainrp就行了
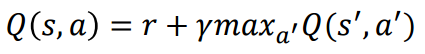

設定每一回合最大訓練步數為10步,超過就進入下一回合重新訓練

這是matlab中秀出圖片的程式,只要給予座標即可產生帶有雜訊圖片

和之前介紹Qlearning地圖的程式一樣,設定policy

設定撞牆就退回原位

[1].Sascha Lange and Martin Riedmiller. Deep auto-encoder neural networks in reinforcement learning. In Neural Networks (IJCNN), The 2010 International Joint Conference on, pages 1–8. IEEE, 2010.
[2].Riedmiller, M. (2005). Neural fitted Q iteration—first experiences with a data efficient neural reinforcement learning method. In Proc. ECML-2005 (pp. 317–328). Berlin, Heidelberg: Springer-Verlag
[3].Riedmiller, M., & Braun, H. (1993). A direct adaptive method for faster backpropagation learning: The Rprop algorithm. In Proc. IJCNN (pp. 586–591). IEEE Press.