
本文要教大家 如何用Q learning 實作出一個走迷宮的AI機器人,如果不知道這公式怎麼來的話可以看我之前的推導文章Q-learning 推導
公式:

程式表示法:
Q(s,a)= oldQ + alpha * (R(s,a,s’)+ (gamma * MaxQ(s’)) – oldQ)
程式碼原檔:https://github.com/darren1231/Reinforcement-learning-q-learning-
歡迎大家下載,是用matlab寫的
如果沒有matlab也沒關係 可以用 Octave 跑也可以,但記得把plot_action 註解掉
完整程式碼解說如下:
主要核心概念就是先做出可以四處走動的機器人,剛開始先用隨機走四個方向,然後再設置牆壁,之後再經由Q learning公式,由最大的Q值決定機器人走向
決定我們的環境狀態怎麼設置,在matlab中起始狀態為1,所以左上角為座標(1,1),如下

所以我們共決定了16個狀態(S),牆壁不算狀態,4個動作(a),下面建立顯示的地圖表示方式,方便查看, 1代表牆壁,Q(s,a)

首先設置一個乾淨的Q table , 我用前面兩個數字的座標當作狀態, 最後面的數字代表動作
![]()
初始化回合數,並設置回合數最大值50
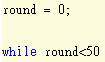
每經過一回合學習,round就++,初始化開始位置(2,2),初始化機器人走路步數(step),您會漸漸地看到機器人每回合走路的step越來越來,直到最後找到最佳路徑

設定學習率0.9 折扣率0.8
![]()
所以總共有兩個迴圈,外層為回合迴圈,內層為步數迴圈,內層迴圈設置直到走回終點(5,5)才會跳出
![]()
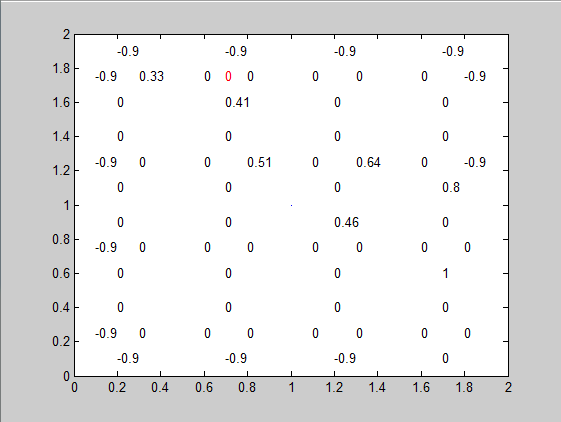
圖形化的工具,因為這Q table是三維的不好觀看,所以我把它圖形化了,第一個參數代表要看的q table,後面的參數代表機器人現在的位置
![]()
機器人現在的位置用紅點表示

亂數產生1~4,代表四個方向
![]()
有了Q table後就可以比較出哪一個 Q(s,a1) Q(s,a2) Q(s,a3) Q(s,a4) 較大,第一個參數代表最大的那個值,第二個參數代表索引值

為了避免q table 剛開始都是0 所以學出來的路徑都一樣,在一開始加點亂數,如果把這個改成一直選最大的Q值也可以,但你會發現學出來的路徑都一樣

在我們的地圖上標記走的步數,如下圖
![]()

紀錄剛剛走過的狀態,也就是state(s)
![]()
根據上面計算的action(1~4),帶入相應動作,走完的狀態我們稱作state(s’)
new_Q(s,a)= oldQ(s,a) + alpha * (R(s,a,s’)+ (gamma * MaxQ(s’)) – oldQ)

判斷撞牆狀態,把機器人退回原位置以及給予reward
由於 new_Q(s,a)= oldQ(s,a) + alpha * (R(s,a,s’)+ (gamma * MaxQ(s’)) – oldQ)
下一個狀態s’是牆壁,可是牆壁不算狀態,所以MaxQ(s’)=0,所以把gamma(b)=0

判斷終點也是一樣的道理
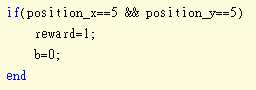
這個就是在找下一個狀態s’的最大Q值 MaxQ(s’)
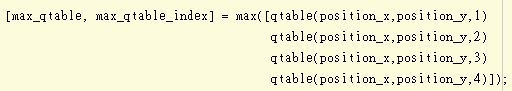
而前面做了那麼多的動作就是為了下面公式的更新 new_Q(s,a)= oldQ(s,a) + alpha * (R(s,a,s’)+ (gamma * MaxQ(s’)) – oldQ)
假設剛剛從狀態 s 執行了a 動作 到 s’ 得到 reward(s,a,s’)
pre_position_x,pre_position_y就代表 s,
action 就代表 a
第二行代入Q learning 更新公式
第三行把算出的新Q value更新回q table中

顯示出每一回合跑了幾步
![]()
像這樣子,第一回合跑了89步,第二回合跑了15步,直到第八回合就收斂到最佳解6步了

你可以在最後看到機器人的最短路徑

當然你也可以運用matlab的debug 功能設置斷點,一步一步的觀察Q table的變動,以及機器人的移動模式,相信會明瞭許多
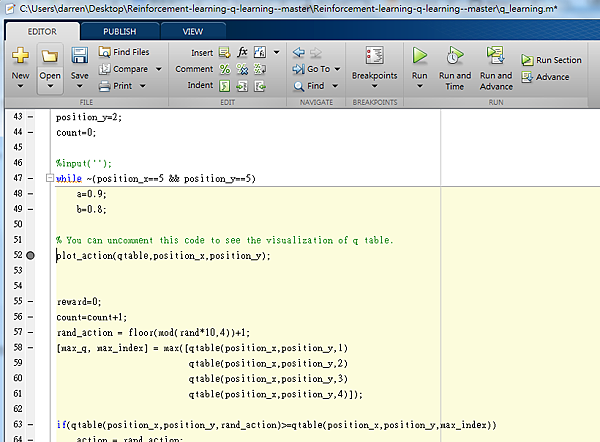
按run 然後按 F5 一次一次的跳到中斷點執行,當然你也可以F10一步一步的執行

matlab 右上角的workspace可以讓你很清楚看到數值的變化
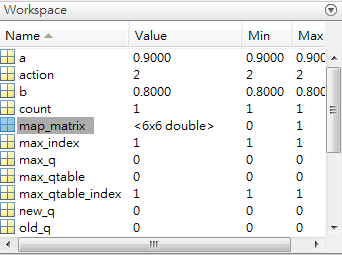
每按一次F5就會有一張圖跑出來,這是S

這是下一個狀態s’,0.47被更新成0.51了

這是收斂後的Q table,你可以仔細觀察它的數字已經不再變化了,也就是說已經達到最佳路徑了
感謝您對reinforcement learning的教學,覺得受益良多。
想請問一下,如果這個程式碼,想改寫為執行動作a時,像之前在DP的教學時一樣,具有某個機率P會發生失誤,也就是有狀態轉移函數T時,整個程式的寫法會需要怎樣修改?
先說我的想法:
1. 直接在line 64後面,判斷完此次動作時,直接考慮P的失誤率來指引到錯誤的方向?
還是
2. 在line 106的附近,update new q時要針對T的引入做其他動作的update?
感謝!
版主回覆:(02/13/2017 09:41:09 AM)
如果是我的話會加在case裏面判斷
因為就是policy不同而已
什麼方法都可以喔
只要意思能對的話 ^.^
感謝您的分享。
想請問這支程式,如果要讓它收斂到某個程度就停止,不用一定要跑到50回合,該如何修改?
因為這個例子是個空間問題比較直觀,可以清楚的知道有沒有收斂,但有些問題如股票交易策略,就不容易知道是否收斂了。
版主回覆:(05/18/2019 04:58:22 PM)
RL的學習問題就是觀看Q值有沒有收斂
因此可以把停止條件設為 new_q 與 old_q 之間的差小於一定
程度的話就可以稱之為收斂了
感謝您的回覆。
new_q 與 old_q 是某個 state 經過訓練後的reward值,原程式中是設定達到目標(5,5)才給 1否則皆為0,因此new_q和 old_q的差常很小,好像不是很好用來判定收斂的條件?
版主回覆:(05/19/2019 04:27:16 PM)
那個Q值是代表未來會獲得的reward加總值
因為有折扣率gamma的關係,所以根據數學算式
一定會收斂到某個數值,不懂的話可以把我之前的文章都看一次喔
有問題歡迎繼續發問 ^.^
你可以仔細的觀察圖形化程式
一步一步地觀看q值的變動,當new_q 與old_q 幾乎不變的時候
我們就會稱作收斂了
感謝您的回覆。
下載的 plot_action函式執行起來有問題,在roundn處會出現錯誤,請問這是matlab的內建函式嗎? 還是要安裝特別的工具箱?
版主回覆:(05/23/2019 02:35:27 PM)
plot action 是我自己寫的函式,你在資料夾中應該就會看到plot_action.m ,此函式接受Qtable與agent 當時候的位置並且回傳圖片