
Chap3:Reinforcement Learning Problem
Markov Decision Processes:

在學習RL之前必須從MDP開始了解起,什麼是MDP呢?大家可以上上維基百科查詢,如同百科上所說的,MDP是一個數學架構模型,他有一個很特殊的性質叫作馬可夫性質, 即系統的未來狀態s(t+1)只與現在狀態s(t)有關,而與之前狀態s(t-1),s(t-2)…..無關,那什麼系統符合MDP呢?舉個簡單的例子,下棋就是一個MDP系統,你下一步該怎麼走s(t+1)只根據你現在的盤面狀態s(t)決定即可,跟你之前走的都沒關係,所以這也是AI常常會以下棋做研究的原因,因為他就是一個標準的MDP系統。了解大概什麼是MDP系統後,我們再細部講解馬可夫對這系統下了什麼定義,馬可夫總共定義了六種東西,分別是:
1.一系列的狀態(s):
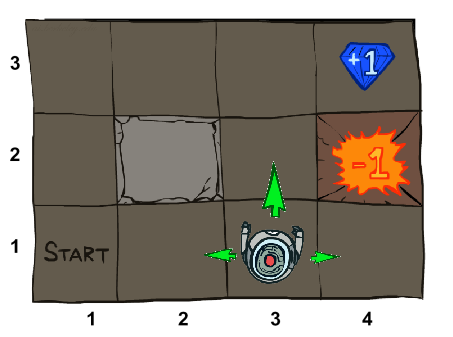
狀態是可以千變萬化隨自己定義的,以上面的走迷宮圖片為例,我定義狀態為機器人到達的不同位置,因此這個環境就產生了12個不同的狀態。
2.一系列的動作(a):
同理也是可以自己定義的,在這個例子中我可以定義動作為上下左右
3.狀態移轉方程式 T(s, a, s’):
紀錄著從狀態s採取動作a到達s’的機率,比如上圖機器人再(3,1)的位置上,機器人採取往上這個動作,正常情況下T(s(3,1), 上, s’(3,2))=1,但在現實生活中呢?你有沒有可能因為輪子打滑而造成採取同樣的動作卻抵達不同的狀態,這個T就是把這個因素考慮進來,所以你如果想要在模擬系統中把這個參數也考慮進去你就可以設T(s(3,1), 上, s’(3,2))=0.8,而分別各有0.1的機率打滑造成抵達狀態的左右兩邊,也就是說
T(s(3,1), 上, s’(4,1))=0.1 不同表示法為:P(s’| s, a)=0.1
T(s(3,1), 上, s’(2,1))=0.1

4.獎勵函數方程式 R(s, a, s’) :
這個是RL學習成功與否的關鍵,你必須告訴機器人,從哪個狀態到哪個狀態是好的,設一個reward獎勵它,就像在教狗狗握手一樣,牠做對了就給牠東西吃(reward=positive),牠做錯了就打牠一下(reward=negative)或擺個生氣的臉,這樣狗狗就知道做錯了,其實RL就是從這樣的一個學習模式演化而來,目的就是為了讓機器人學會某一件事(狗狗握手),差別是我們把他數學化了,數學話的目的為了好進行公式推導演算,簡單的來說呢就是使機器人得到的reward最大化就是RL在解決的問題。拿這個地圖範例來說,我們想要機器人走到終點(4,3),遠離火堆(4,2),因此我們可以設定 R(s(3,3), 右, s’(4,3))=1 R(s(3,2), 右, s’(4,2))=-1 ,來使機器人學會避開火堆到達終點的最短路徑。
5.起始狀態(start state):定義系統的初始狀態(1,1)
6.結束狀態(terminal state):定義系統的終點位置(4,3)
維基百科參考資料:
MDP:
在機率論和統計學中,馬可夫決策過程(英語:Markov Decision Processes,縮寫為 MDPs)提供了一個數學架構模型,用於面對部份隨機,部份可由決策者控制的狀態下,如何進行決策,以俄羅斯數學家安德雷·馬爾可夫的名字命名。在經由動態規劃與強化學習以解決最佳化問題的研究領域中,馬可夫決策過程是一個有用的工具。
Markov property:
馬可夫性質(英語:Markov property)是機率論中的一個概念,因為俄國數學家安德雷·馬可夫得名。當一個隨機過程在給定現在狀態及所有過去狀態情況下,其未來狀態的條件機率分布僅依賴於當前狀態;換句話說,在給定現在狀態時,它與過去狀態(即該過程的歷史路徑)是條件獨立的,那麼此隨機過程即具有馬可夫性質。具有馬可夫性質的過程通常稱之為馬可夫過程。
再來我從學習率的概念帶大家一步一步進入RL的世界,書上通常從這個例子 armed-bandit problem開始介紹起,中文的翻譯為吃角子老虎機。
學習率(α)的概念: learning rate
假設你去玩吃角子老虎機


你想要知道哪一台最好中獎,所以你每一台都去玩看看,玩第一次看贏了多少錢稱做R1,第二次賺得獎勵稱做R2,所以玩了K次之後取平均得到Q,Reinforcement learning 的主要任務就是最大化這個Q值,Q值越大代表我獲得的獎金最多,沒有人玩吃角子老虎機是想要賠錢的吧?
但是這裡有一個問題,我每玩一次就必須要記錄前幾次得到的R,那如果我只想記錄前面一次節省記憶體該怎麼做呢? 下面就是推法
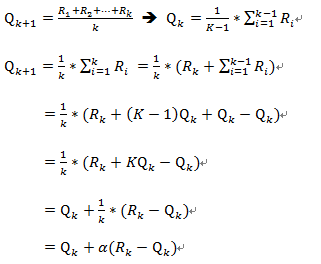


折扣率(γ)的概念: discounting rate
但是我們等下要推的不是過去的經驗,我們想預測未來,所以Gt代表預測未來的R總和,等差級數一直加到最終回合出現,但這會產生一個問題,如果遇到沒有最終回合的情況一直加下去的話,G將會呈現無限大,這不利於我們之後的計算,因此要乘以一個折扣率衰減,所以式子呈現如下,第三行為無最終回合的表示方法,第四行為有最終回合的表示方法。
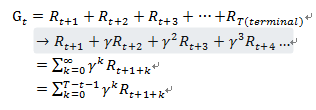

Bellman equation:
接下來我們要來推鼎鼎有名的Bellman equation,Vπ(s)代表在狀態為s的情況下,策略(policy)為π時G的期望值,我們所要做的就是推出像剛剛推吃角子老虎機的公式一樣,推出動態方程式,下面即為推出的過程。
r(s,a,s’)代表在狀態s下採取a這個動作會造成狀態移轉到下一個狀態s’


如果看不懂的話,小編也有一個自己的理解方法如下:

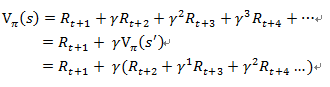
總之就是要推出 ![]()
 這個遞迴的Bellman equation
這個遞迴的Bellman equation 
我只是簡化推倒過程方便大家看得懂,但書上把policy還有transition probabilities都考慮進去了,書上完整推導如下:

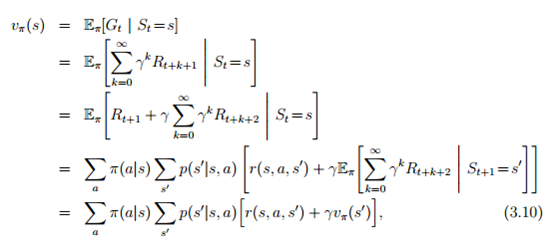

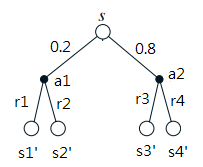

假設移轉機率都為0.5,小編試算上面這個s給大家看



講完了V值再來講q值,理念都是一樣的,只是這裡的狀態空間多一維action

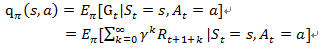
上面推的是任意policy下(π),Bellman equation都應該被滿足,那麼當policy 是 optimal policy 時當然也應該被滿足啊,因此我們將最佳策略表示成(*):
原文對照:
Intuitively, the Bellman optimality equation expresses the fact that the value of a state under an optimal policy must equal the expected return for the best action from that state:
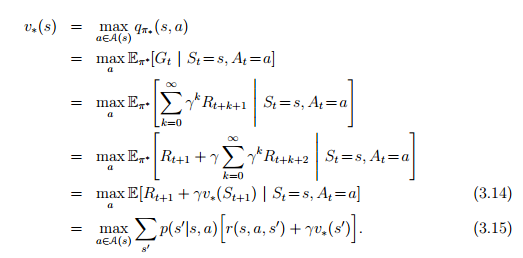

The last two equations are two forms of the Bellman optimality equation for
v∗. The Bellman optimality equation for q∗ is
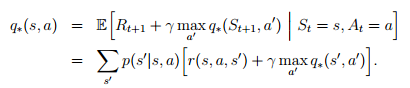

下圖即為常見的RL學習系統的表示圖,根據您定義的方法針對環境給予reward以及切割狀態,機器人會一步一步的學會在什麼狀態下要執行什麼動作,這個過程我們就稱作policy 學習,下面就是要講如何學習這個policy。


請問q是什麼?Q和q之間的關係是?
謝謝
版主回覆:(01/11/2017 03:39:42 PM)
您好~大Q 只是要介紹學習率的概念
因為課本也是用大Q,我就依照課本沒改了
所以大Q 小q是沒關係的
在RL中有兩個東西要分清楚
一個是q稱做action value
一個是V稱做state value
q_pi(s,a)是代表做了a這個動作後採取pi這個策略後所獲得的reward加總值。
最近有弄了一份新的文件了,但是是用word寫的,想把他轉成html檔,可是公式還有圖片格式都不對,需要研究一下XD
您好。
最近正在讀RL。路過看見此篇文章,覺得之前懵懵懂懂的概念又更清晰了!
版主回覆:(03/25/2017 11:08:20 AM)
我也是過來人阿~加油XD
另外想請問一下,您是參考哪本書呢?
謝謝!
版主回覆:(03/25/2017 11:13:25 AM)
這個網頁有說
http://darren1231.pixnet.net/blog/post/336499847-reinforcement-learning—q-learning-%E6%8E%A8%E5%B0%8E
我是參考Sutton 寫的 RL 聖經,如果想讀懂的話 建議買一本最好
我的都翻到快爛掉了才懂一點點的,真心覺得他好厲害~~
那個,「假設移轉機率都為0.5,小編試算上面這個s給大家看」這句話下面那張圖裡面的0.2*0.5+(r1+v(s’))的加號是否應該是乘號呢?
版主回覆:(04/23/2017 12:22:04 AM)
恩恩 謝謝~~已改正
版大好
請問q*(s,a) 是不是比 v*(s) 多搜尋一層未來的最佳狀態?
謝謝.
版主回覆:(04/30/2017 09:19:23 PM)
Q 和 V 的不同點就是 Q 會多了一個動作維度喔
如果你指的多一層是指動作維度
那答案 就是 是囉~~
版大好
也就是說q*(s,a)會使用到s’及s"的值嗎?
版主回覆:(05/01/2017 02:38:54 PM)
不是很懂你想要表達的意思
是指做疊代運算的時候嗎?
疊代運算的時候的確會用到下個狀態S’ 但不會有下下個狀態S”
根據Sutton 的 book 公式(2.3)前一段的敘述“ For some action, let Q_k denote
the estimate for its kth reward, that is, the average of its first k − 1 rewards.”
意思是 Q_k = R_k = 前k-1次的reward 平均嗎?
假如是的話,為何這一次的reward會是前幾次的平均? 是作者的定義嗎?
版主回覆:(05/04/2017 08:38:07 PM)
這個我上面有提到喔
在吃角子老虎機的下面
這裡只是在講一個遞迴的概念
我們不必把每一次所獲得的reward都存在記憶體中
根據公式推導,我們可以記錄前面K-1次的平均 還有第K次所獲得的reward即可得知前K次所獲得reward的平均
課本用的代號是Q,是的 他定義Q(K)是前面k-1次所獲得reward的加總取平均,因此你的公式應該是錯的,不是Q(K)=R(k),是
Q(K)=sigma_i(1->k-1) R(i)/(k-1) 相當於前面K-1次的reward平均
這個對,中間錯了
你好 繼續請教, 課本那一段話 let『 Q_k denote the estimate for its kth reward』, that is the average of its first k − 1 rewards.,
『』那段話是什麼意思,謝謝.
版主回覆:(05/05/2017 03:31:57 PM)
了解,我大概懂你想說的點了
課本的意思是說 "估計"第K次所獲得的reward
而他估計的方法就是採用加總前K-1的reward然後取平均
這樣的解釋不知您可以接受嗎? XD
了解 謝謝你
也就是說 這應該是作者的定義(假設),他假設第K次所獲得的reward,就相當於加總前K-1的reward然後取平均,只是有點好奇為什麼會這樣假設(估計)?!
總之,謝謝你的解釋.
版主回覆:(05/08/2017 05:29:20 PM)
是的,至於為什麼?
應該是因為可以推出後面的東西吧
—遞迴關係式的概念—
數學很漂亮~~^.^ 超佩服作者的~~
我想,取平均值是為了不讓數值一直壘加到爆炸的方式.
版主回覆:(05/10/2017 10:59:25 AM)
恩恩 也可以這麼想~
你好,感謝你的整理,想請問這是參考哪一本教科書的內容呢?
版主回覆:(03/24/2020 11:49:43 PM)
我是參考sutton 寫的聖經喔
An introduction to reinforcement learning