- Hugging Face 是一個知名的人工智慧與機器學習平台,致力於為開發者和研究者提供高效的開源工具與模型。Stable Diffusion 是由 Stability AI 開發的圖像生成模型,能根據文本描述創建高品質的圖像,結合 Hugging Face 的平台優勢,進一步推動了生成式 AI 的應用。
- Stable Diffusion 是基於擴散模型的技術,透過逐步還原噪音的過程生成影像。其強大的能力不僅支持藝術創作、遊戲設計,還能用於廣告、教育和科研等多領域。Hugging Face 提供簡單易用的 API 與介面,開發者可以輕鬆地將 Stable Diffusion 模型整合到自己的應用中,無需深厚的技術背景。
- 下面將介紹大家如何使用這個模型來創造有趣有好玩的圖片
安裝環境
pip install diffusers transformers accelerate scipy safetensors使用方法
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "stabilityai/stable-diffusion-2-1"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
- 輸出結果
- 權重儲存: 執行完的權重會存在cache資料夾中
- ls ~/.cache/huggingface/diffusers/

- 使用參數
- prompt (
str
orList[str]
, optional) — The prompt or prompts to guide image generation. If not defined, you need to passprompt_embeds
. - height (
int
, optional, defaults toself.unet.config.sample_size * self.vae_scale_factor
) — The height in pixels of the generated image. - width (
int
, optional, defaults toself.unet.config.sample_size * self.vae_scale_factor
) — The width in pixels of the generated image. - num_inference_steps (
int
, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. - timesteps (
List[int]
, optional) — Custom timesteps to use for the denoising process with schedulers which support atimesteps
argument in theirset_timesteps
method. If not defined, the default behavior whennum_inference_steps
is passed will be used. Must be in descending order. - sigmas (
List[float]
, optional) — Custom sigmas to use for the denoising process with schedulers which support asigmas
argument in theirset_timesteps
method. If not defined, the default behavior whennum_inference_steps
is passed will be used. - guidance_scale (
float
, optional, defaults to 7.5) — A higher guidance scale value encourages the model to generate images closely linked to the textprompt
at the expense of lower image quality. Guidance scale is enabled whenguidance_scale > 1
. - negative_prompt (
str
orList[str]
, optional) — The prompt or prompts to guide what to not include in image generation. If not defined, you need to passnegative_prompt_embeds
instead. Ignored when not using guidance (guidance_scale < 1
). - num_images_per_prompt (
int
, optional, defaults to 1) — The number of images to generate per prompt. - eta (
float
, optional, defaults to 0.0) — Corresponds to parameter eta (η) from the DDIM paper. Only applies to the DDIMScheduler, and is ignored in other schedulers.
- prompt (
- Text to image arena
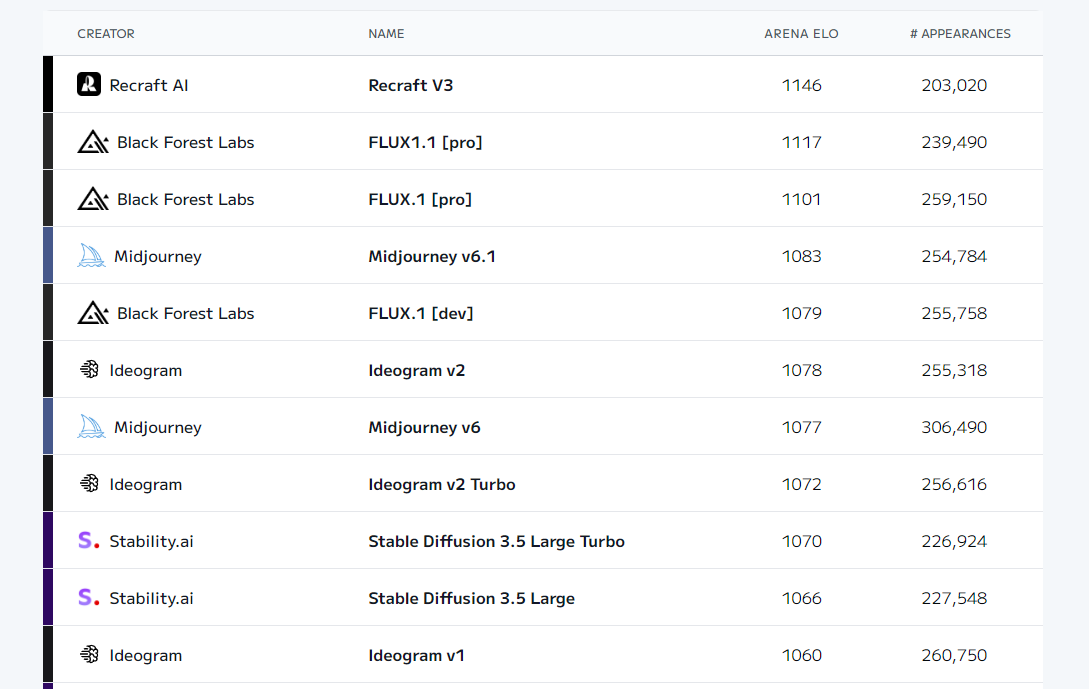
- 下圖是目前世界的排名,上面介紹的stable-diffusion-2-1 ELO分數大概為749
- 下圖是目前世界的排名,上面介紹的stable-diffusion-2-1 ELO分數大概為749
- 參考資料
- stabilityai/stable-zero123 · Hugging Face
- OpenAI Dalle-3 API in Python : Text to Image Generation (Full Tutorial) – YouTube
- Text to Image Model Arena | Artificial Analysis
- Text-to-image
- stabilityai/stable-diffusion-2-1 · Hugging Face
- 如何從 HuggingFace 下載模型 – ChiChieh Huang – Medium
- [大模型通用版]最新地面最强服务器部署hugging face大模型方法之stable diffusion_hugging face stable diffusion-CSDN博客
- 到底 Stable Diffusion 有多少個版本?