
Adagrad gradient descent implement
今天小編要教大家實作網路的梯度下降法,並用圖式化的方法一步一步的看出演算法的學習過程,非常適合初學者建立梯度下降法的概念,全文會公式與程式碼並行並搭配圖片讓概念更加具體化,本教學是看到台大李弘毅老師的課程因而寫的,老師在影片中說得很棒,很適合初學者學習,推薦大家去看老師的影片,底下附上影片連結,本篇只是以文字的方法描述老師影片所講解的內容而已。
開始之前先解釋一下程式碼的概念,首先會有10組創造出的data,接著將透過演算法找尋適合的weight、bias,使得用這組w、b預測出來的 y 值會最接近提供的數據,並讓Error加總最小。創造Error function有多種形式,這裡採取最簡單的square error做講解。
公式如下:
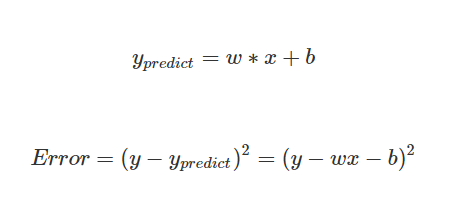
提供的10組數據:
x_data = [ 338., 333., 328. , 207. , 226. , 25. , 179. , 60. , 208., 606.]
y_data = [ 640. , 633. , 619. , 393. , 428. , 27. , 193. , 66. , 226. , 1591.]
創造數據集
首先介紹contour圖,橫軸代表bias,從-200~~-100(step=1),共有100個點,縱軸代表weight,從-5~~5(step=0.1),也是100個點,將這兩組100個點以meshgrid的方式即可產生出二維矩陣以方便畫圖。顏色越偏紅色代表Error越高,越偏藍色代表Error越低。而橘色的X所在位置即代表Error最小的地方,也就是最佳解的位置(w=2.67,b=-188.4)

實作梯度下降法

b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n])*1.0
w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n] 實作SGD 演算法
接下來就可以把所有程式碼整合再一起,利用一次又一次的疊代算出每次更新後的w、b,並創造一個list儲存歷史算出的紀錄以便畫在圖上,底下為計算梯度的程式碼:
1e-7:
將學習率設為1e-7後可以發現疊代100000次後依然是離最佳解相當的遙遠

lr=1e-6
將學習率變大10倍後可以發現又更接近一些了

lr=1e-5
但再繼續調大10倍後發現算出的解答已經亂跳了,超出圖片範圍了,這就是SGD的詬病,必須選定一個適當的學習率,選擇太大的話就會造成如下圖的現象發生

Adagrad 公式
因此就有人提出 adagrad演算法,這演算法在前期的時候可以放大梯度,因為前期g的加總是小於1的小於1的值開根號會越開越大,而後期的時候因為累加的數字大於1了就會造成開根號的值越來越小,因此後期有約束梯度的現象,整體公式如下,其中 ϵ 為一個極小值,為的是避免分母為0的現象發生,但在本程式中沒有考慮這項:
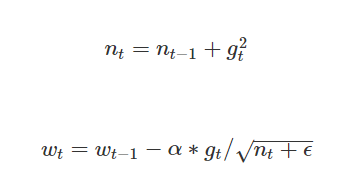
將演算法改為adagrad的完整程式碼如下,大家可以兩份code互相比較一下即可知道不同點在哪
更改為adagrad演算法後,學習率隨便設個1就可以快速的到達最優解的位置了

參考資料:
1.https://zhuanlan.zhihu.com/p/22252270
2.https://www.youtube.com/watch?v=1UqCjFQiiy0&index=4&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49