
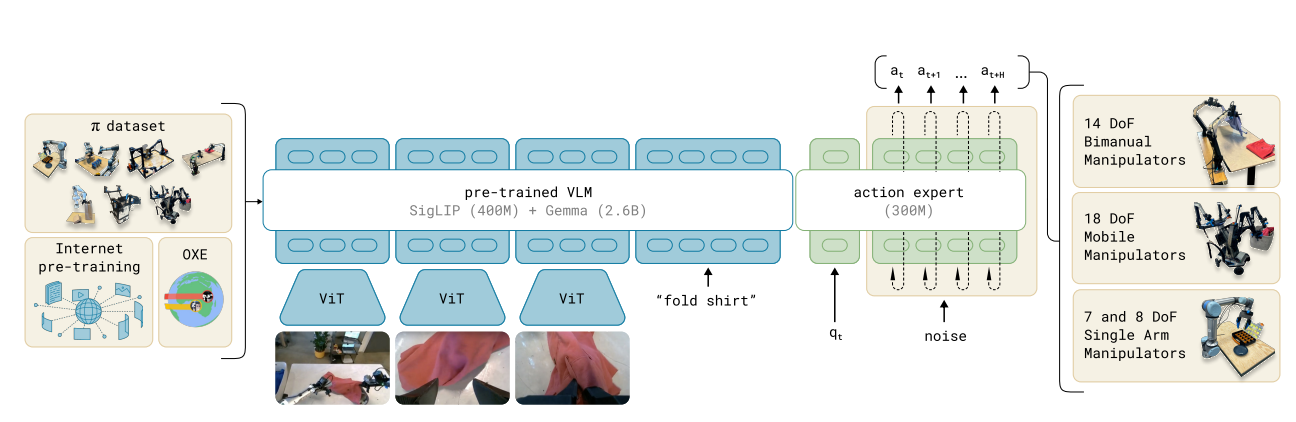
技術背景與理論基礎
- 能解決什麼問題: 目前的機器人學習在數據量、泛化性與魯棒性方面面臨重大障礙。雖然大型語言模型(LLM)具備強大的語義推理能力,但它們不具備實體(Embodied)經驗,對物理交互的理解僅限於抽象描述。$π0$ 旨在建立一個具備通用性且能執行複雜靈巧操作(如摺疊衣物、組裝紙箱)的機器人基礎模型,並解決數據稀缺導致模型無法從錯誤中恢復的問題
- 技術發展簡史: 早期的機器人學習多集中於簡單任務(如抓取或推動)的自監督學習。近期,雖然已開發出如 RT-2 等視覺-語言-動作(VLA)模型,但這些模型通常使用離散的 Token 來表示動作,難以處理高頻率且精細的控制任務, 因此本論文提出流匹配結合 VLA 模型的技術能解決離散token 不準確的痛點
- 相關理論和技術基礎:
- 視覺-語言模型 (VLM): $π0$ 基於前作 OpenVLA 做修改, 改善了OpenVLA 不能連續且只能訓練一個機械手臂的痛點
- 跨機器人構型訓練 (Cross-embodiment Training): 結合來自多種不同型號機器人的數據進行訓練,以提升泛化能力。
- 流匹配 (Flow Matching): 一種擴散模型(Diffusion)的變體,用於表示複雜的連續動作分佈
- 核心算法或模型解釋
- 主要算法及其數學模型: $π0$ 使用條件流匹配(Conditional Flow Matching)來建模動作。
- 原始流匹配函數
- 原始的流匹配損失函數如下: \(L(θ)=E_{τ,x0,x1}∣∣v_θ(x_τ,τ)−u(x_τ)∣∣^2\)
- \(L(θ)\):代表模型的損失值(Loss)。訓練的目的就是透過梯度下降,找到一組參數 \(θ\) 來最小化這個損失值
- \(θ\):代表模型中所有可學習的權重參數
- \(E\):代表期望值(Expectation)。在機器學習中,這意味著我們無法計算所有可能的數據組合,因此透過從特定分佈中隨機「採樣」大量樣本來計算平均誤差
- \(τ\) (Tau):流匹配時間步,取值範圍為 。它描述了數據從「純噪聲」轉變為「真實數據」的過程。在 \(π0\) 中,模型會特別加強對低 \(τ\)(高噪聲水平)的採樣,以增強錯誤恢復能力
- \(x0\):代表起始分佈(簡單分佈)。在論文中通常指隨機高斯噪聲 \(ϵ∼N(0,I)\)
- \(x1\):代表目標分佈(複雜數據分佈)。在 $π0$ 的語境下,這就是人類專家執行的真實動作塊
- \(x_τ\):代表在時間步 $τ$ 時的中間含噪狀態。它是在噪聲 $x0$ 與真實數據 $x1$ 之間進行線性插值得到的結果,公式為 $xτ=τx1+(1−τ)x0$
- \(vθ(xτ,τ)\):這是由神經網路(模型)預測的向量場(Vector Field)。模型觀察目前的模糊狀態 \(xτ\) 和時間步 \(τ\)(在 $π0$ 中還會加入環境觀察 $ot$),然後猜測:「若要變回真實動作,我現在該往哪個方向、以多快的速度移動?
- \(u(xτ)\):這是目標向量場(Target Vector Field),即「標準答案」。在 \(π0\) 採用的線性路徑下,這個正確的方向被定義為 \(u=x0−x1\)(在源文件中表示為 $ϵ−At$),這是一個直接指向目標的恆定向量
- \(∣∣…∣∣2\):這是 L2 範數(歐幾里得距離)的平方。它衡量模型預測的方向 $vθ$ 與正確方向 $u$ 之間的差距
- 基礎含意:模型在練習成為一個導航員。我們隨機選一個時間點 \(τ\),給它一個模糊的信號 \(xτ\),要求它預測的向量 \(vθ\) 必須跟正確的導航指令 \(u\) 越接近越好
- 損失函數: \(Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∣∣vθ(Atτ,ot)−u(Atτ∣At)∣∣2\)。
- \(Lτ(θ)\): 這是模型在特定流匹配時間步 \(τ\) 下的損失值。\(θ\) 代表模型(神經網絡)的參數,訓練的目標就是最小化這個損失。
- \(Ep(At∣o_t),q(A^t_τ∣At)\): 這代表期望值(Expected Value)。意指模型會在兩個分佈中進行採樣計算平均誤差:
- ◦ \(p(At∣o_t)\):從訓練數據集中取樣,即在給定觀察 $ot$(圖像、指令、狀態)的情況下,真實的專家動作 $At$ 是什麼。
- ◦ \(q(A^t_τAt)\):取樣「機率路徑」中的中間狀態,即將真實動作與噪聲混合後的狀態。
- \(vθ(A^t_τ,ot)\): 這是模型預測的向量場(Vector Field)。
- ◦ 它接收當前的「含噪動作」 $A^t_τ$ 以及環境觀察 $o_t$ 作為輸入。
- ◦ 它的任務是預測在時間步 $τ$ 時,數據應該往哪個方向「流動」才能變回真實動作。
- \(u(Atτ∣At)\): 這是目標向量場(Denoising Vector Field),也是模型學習的「正確答案」。
- ◦ 在 \(π0\) 所採用的線性高斯路徑中,這個目標被定義為 \(u=ϵ−At\)(其中 $ϵ$ 為隨機噪聲)。
- ◦ 它指引模型如何從帶有噪聲的狀態 \(Atτ\) 回推到原始動作 \(At\)。
- 5. \(∥…∥2\): 這是 L2 範數(歐幾里得距離)的平方,用來衡量模型的預測值 \(vθ\) 與目標值 \(u\) 之間的差距。
- 補充:機率路徑的構成
- 公式中提到的 \(Atτ\)(含噪動作) 是透過以下方式計算的: \(Atτ=τAt+(1−τ)ϵ\)
- \(τ\):流匹配時間步,介於 0 到 1 之間。
- \(ϵ\):從標準正態分佈 \(N(0,I)\) 中取樣的隨機噪聲。
- 當 \(τ=0\) 時,\(Atτ\) 是純噪聲;當 \(τ=1\) 時,\(Atτ\) 就是真實動作。
- 這個公式的本質是讓模型學習一組「導航指令」(向量場),好讓機器人能從混亂的隨機狀態中,精準地勾勒出符合當前環境(\(ot\))的連續動作序列
- 訓練邏輯: 採樣隨機噪聲 \(ϵ\),生成含噪動作 \(Atτ=τAt+(1−τ)ϵ\),並訓練網路 $vθ$ 預測去噪向量場 \(u=ϵ−At\)。
- 推理過程: 從純噪聲開始,透過 10 步的 Euler 積分 沿著預測的向量場移動,最終生成動作。
- 原始流匹配函數
- 核心技術概念的分解與說明:
- 動作專家 (Action Expert): 這是額外增加的 3 億參數模塊,專門處理機器人的本體感受狀態(Proprioceptive state)與動作 Token,與主幹 VLM 透過自注意力機制交互。
- 動作分塊 (Action Chunking): 模型一次預測未來 50 步的動作序列(\(H=50\)),這使其能以高達 50 Hz 的頻率進行高頻控制。
- 非均勻時間步採樣: 使用 Beta 分佈來採樣流匹配時間步 $τ$,強調較高噪聲水平的學習,這有助於模型學習如何從錯誤中恢復
- 主要算法及其數學模型: $π0$ 使用條件流匹配(Conditional Flow Matching)來建模動作。
- 實驗效果
- 圖 7:基礎模型「開箱即用」能力評估 (Out-of-box Performance)
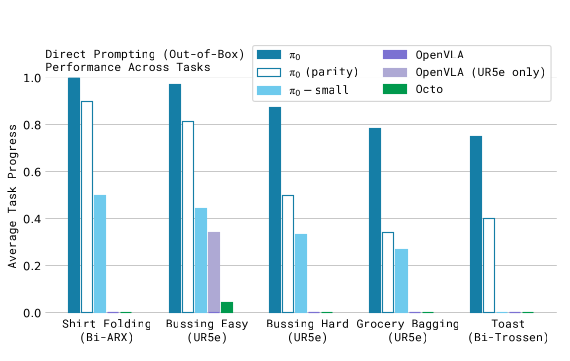
- 這張圖展示了模型在預訓練完成後、未經任何特定任務微調(Fine-tuning)的情況下,僅憑語言指令(Prompting)執行任務的表現。
- • 比較對象:\(π0\)(完整訓練 700k 步)、\(π0\)-parity(為公平競爭僅訓練 160k 步)、\(π0\)-small(無 VLM 預訓練的小模型)、以及 OpenVLA 與 Octo 等現有的機器人基礎模型。
- • 實驗任務:包含摺疊襯衫、簡易/困難桌面清理、雜貨裝袋及從烤麵包機取出土司。
- • 關鍵結論:
- ◦ 壓倒性勝利:$π0$ 在所有任務中表現均遠優於 OpenVLA 和 Octo。即便是在訓練步數相同(160k 步)的情況下,$π0$ 依然勝出。
- ◦ 架構優勢:OpenVLA 因為不支援「動作分塊(Action Chunking)」與高頻控制,在這些靈巧任務中表現掙扎;而 $π0$ 結合流匹配(Flow Matching)技術,能精準處理 50Hz 的連續動作
- 圖 9:語言指令遵循能力評估 (Language Following)
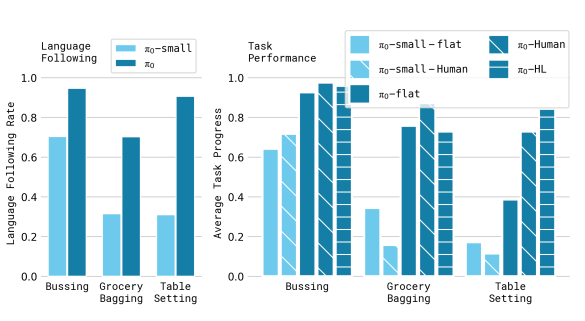
- 這張圖探討了模型對語言指令的理解深度,以及是否能透過「高層級指令」提升任務成功率。
- • 比較變數:
- ◦ Flat:僅給予總體目標(如「清理桌子」)。
- \(π0\)-human:代表由人類專家(Human expert)提供中間步驟指令。例如,人類會告訴機器人「拿起叉子」或「將其放入桶中」等具體步驟。
- ◦ \(π0\)-HL:代表由高層級 VLM 策略(High-level VLM policy)自動產生的指令。這是一個自動化(Autonomous)的過程,不需人類干預,利用類似 SayCan 的方法將複雜任務分解為子任務
- • 關鍵結論:
- ◦ VLM 預訓練的重要性:$π0$ 在遵循複雜指令的能力上顯著優於沒有 VLM 初始化背景的 $π0$-small。
- ◦ 效能提升:當引入中間步驟指令時,$π0$ 的成功率大幅提升,這證明了模型具備將語義指令轉化為物理動作的強大能力
- 圖 11:不同數據量的微調效果 (Fine-tuning Analysis)
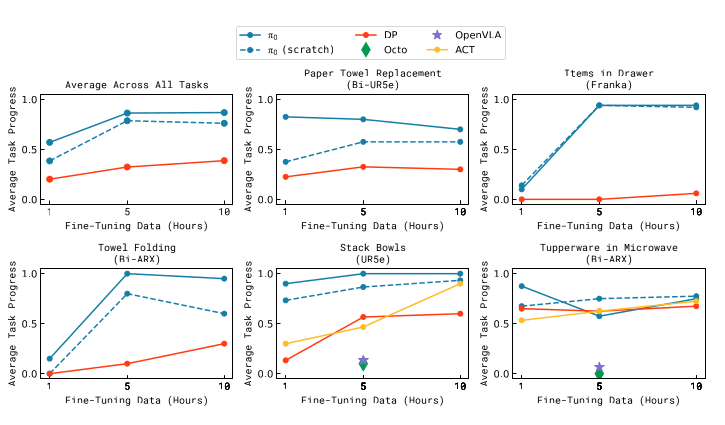
- 這張圖測試了模型學習全新任務的速度,特別是當訓練數據(微調數據)非常有限時的表現。
- 實驗設計:提供 1 小時、5 小時及 10 小時的微調數據,觀察模型在「疊碗」、「微波爐加熱」、「更換紙巾」等新任務中的進展。
- 關鍵結論:
- 預訓練的優勢:在大多數任務中,經過預訓練的 $π0$ 比「從零開始訓練(Scratch)」的模型表現更好,且通常僅需 1 小時的數據就能達到甚至超越其他基準模型(如 ACT、Diffusion Policy)使用更多數據的效果。
- 快速適應:對於與預訓練數據相似的任務(如摺疊毛巾),預訓練帶來的效能提升尤為顯著
- 圖 13:複雜多階段任務的最終表現 (Complex Multi-stage Tasks)
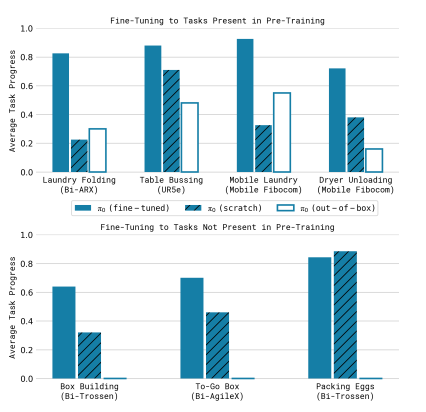
- 這張圖展示了 $π0$ 處理極高難度、長時間任務的極限能力,這些任務通常需要數十分鐘才能完成。
- 實驗任務:包含摺疊大量衣物、移動式機器人摺衣、組裝完整的瓦楞紙箱、裝填雞蛋以及清理真實的午餐桌面。
- $π0$ (out of the box):有 10,000 小時預訓練,沒有特定任務微調。
- $π0$ (fine-tuned):有 10,000 小時預訓練,加上針對特定複雜任務的高品質微調。
- $π0$ (scratch):沒有這 10,000 小時的預訓練,直接從頭學習特定任務
- 關鍵結論:
- 全配方的必要性:實驗顯示,「預訓練 + 微調」的完整流程(Full recipe)在所有困難任務中均取得最高分。
- 對抗脆弱性:單純微調(Scratch)的模型在遇到錯誤時缺乏恢復能力,而經過大規模預訓練的 $π0$ 則展現了極強的魯棒性,能處理未見過的物體配置與物理干擾。
- 技術突破:在組裝紙箱或裝填雞蛋等需要雙臂協作與靈巧力量控制的任務中,$π0$ 達到了目前機器人學習領域的新高度
- 圖 7:基礎模型「開箱即用」能力評估 (Out-of-box Performance)
- 優缺點分析
- 優點:
- 高靈巧度與精確度: 透過流匹配處理連續動作,能執行極細緻的操作。
- 泛化性強: 繼承了 VLM 的通用知識,且具備強大的錯誤恢復能力(來自多樣化的預訓練數據)。
- 多構型適配: 單一模型即可控制單臂、雙臂、移動式等多種機器人
- 缺點:
- 計算資源需求: 推理時需要多次前向傳遞(10 步積分),雖然已優化,但仍存在一定的延遲(
- 數據依賴性: 複雜任務仍需針對性地收集高品質數據進行微調才能達到完美效果。
- 領域局限性: 雖然在操縱領域表現優異,但其通用性是否能擴展至自動駕駛、腿式機器人等領域仍待研究
- 優點:
- 鑑往古今
- RT-2: 使用自回歸離散化來表示動作的 VLA 模型,但在高頻任務上表現受限。
- OpenVLA: 最剛開始公開的VLA 模型
- Octo: 基於擴散過程的通用機器人策略模型。
- ACT & Diffusion Policy: 專為學習靈巧任務設計的架構,通常針對單一任務從小規模數據中學習。
- Transfusion: 同時預測離散 Token 與連續輸出的 Transformer 架構,為 $π0$ 提供了設計靈感
- 名詞解釋
- VLA (Vision-Language-Action): 將視覺影像、語言指令與機器人動作整合在單一模型中的架構。
- Flow Matching (流匹配): 一種生成式建模技術,透過學習向量場來定義數據與噪聲之間的轉換路徑。
- Action Chunking (動作分塊): 一次預測並執行一段時間內的動作序列,而非單一步驟,有助於提高動作流暢度。
- Cross-embodiment (跨構型): 指模型能夠處理來自不同物理結構(如不同品牌或類型的機械臂)的機器人數據。
- Proprioceptive State (本體感受狀態): 機器人自身的物理資訊,如關節角度或末端執行器的位置
- 參考資料
- PaliGemma: A versatile 3B VLM for transfer (Beyer et al., 2024).
- Flow Matching for Generative Modeling (Lipman et al., 2022).
- Open X-Embodiment: Robotic learning datasets and RT-X models (2023).
- RT-2: Vision-Language-Action models transfer web knowledge to robotic control (Brohan et al., 2023).
- Diffusion Policy: Visuomotor policy learning via action diffusion (Chi et al., 2023)
- https://blog.csdn.net/nenchoumi3119/article/details/148689279
- https://zhuanlan.zhihu.com/p/1973166010707248402