
- 技術背景與理論基礎
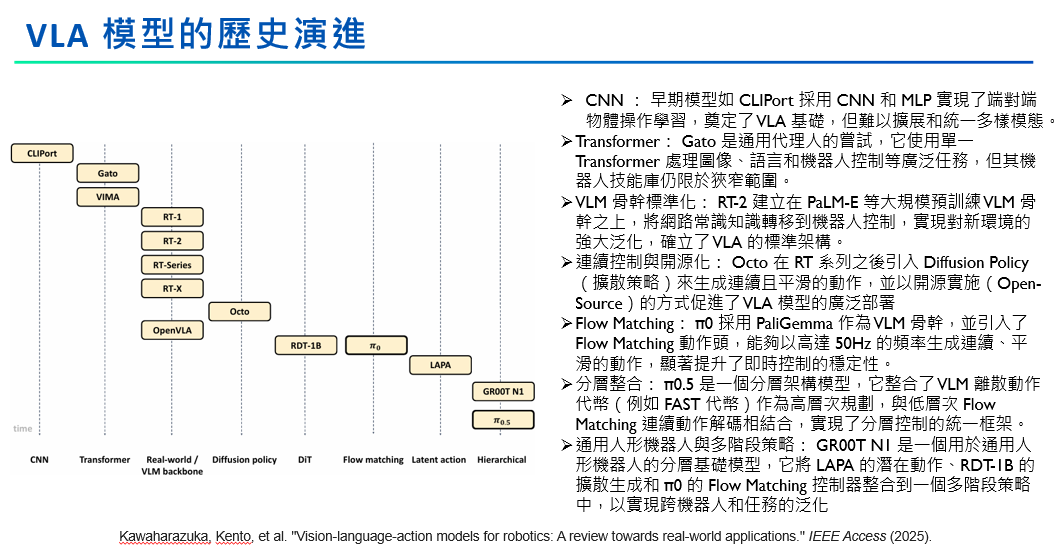
- 歷史演進
- OpenVLA 模型的開發旨在解決通用機器人策略的兩個主要障礙:
- 1. 現有 VLA 模型的封閉性與難以取得性:現有的視覺-語言-動作模型 (VLA) 大多數是閉源的 (largely closed),公眾難以取得和使用。這限制了未來對於 VLA 訓練、數據混合、目標和推理的進一步研究。
- 2. 缺乏高效微調方法:先前的工作未能探索有效微調 VLA 模型以適應新任務的方法,而這是 VLA 普及的關鍵組成部分。現有工作也沒有提供在消費級硬體(如消費級 GPU)上部署和適應 VLA 的最佳實踐。
- 3. 傳統策略的泛化能力不足:傳統為單一技能或語言指令訓練的機器人策略,雖然能夠推斷新初始條件下的行為,但對於場景干擾物、新物體缺乏穩健性,且難以執行未見過的任務指令。
- 理論基礎
- 大型語言模型 (LLM) 骨幹: OpenVLA 建立在 Llama 2 7B 參數的大型語言模型 (LLM) 骨幹之上。
- 基礎 VLM 架構: OpenVLA 使用了 Prismatic-7B VLM 作為其預訓練的骨幹。Prismatic VLM 遵循標準 VLM 架構,包含一個視覺編碼器、一個投影儀(2 層 MLP)和 Llama 2 7B 語言模型骨幹。
- 融合視覺編碼器: OpenVLA 的視覺編碼器使用了兩個預訓練模型的特徵融合:DINOv2 和 SigLIP。這種雙組件視覺編碼器被證明有助於改進空間推理能力。
- 大規模訓練數據: OpenVLA 是在來自 Open X-Embodiment 資料集 的 970k 機器人情節(即機器人示範數據)上進行微調的。這個數據集涵蓋了廣泛的機器人實體、任務和場景
- 歷史演進
- 核心算法或模型解釋
- 核心算法
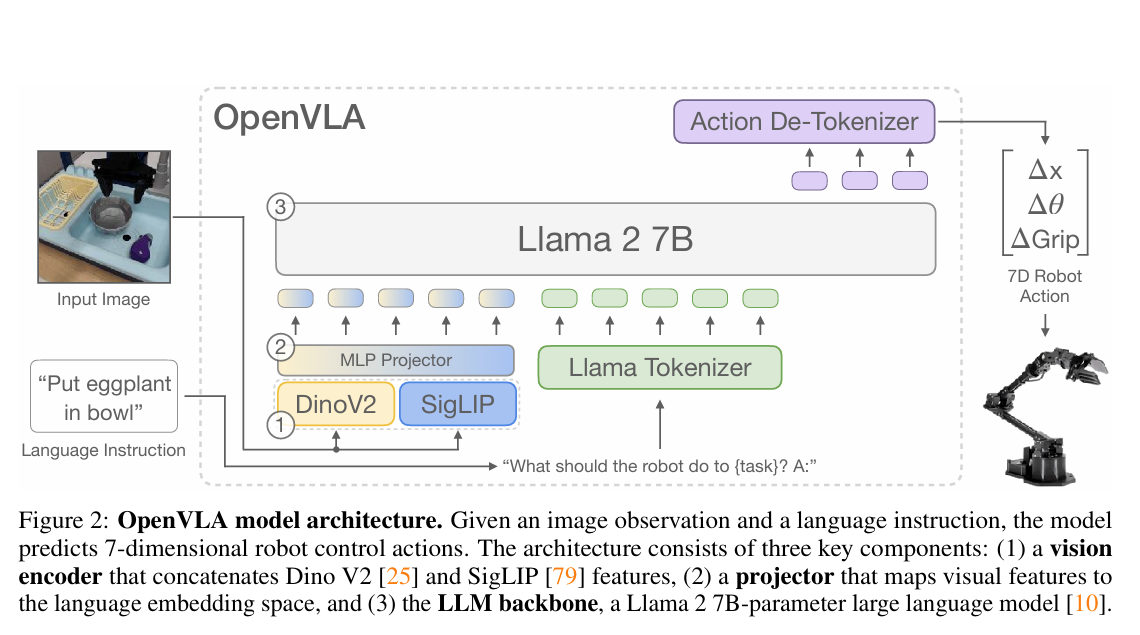
- OpenVLA 使用大語言模型llama 2 當成基礎, 輸入一張圖片與相對應的提示詞就可以輸出機器人的相關動作,特別注意的是,這裡輸出的動作都是和前一個相比,因此是相對值而不是絕對值
- OpenVLA 在上述基礎上進行了幾項關鍵的設計決策和優化,以提升其作為通用機器人策略的性能和實用性:
- 1. 架構和訓練優化(為機器人控制量身定制)
- 微調視覺編碼器 (Fine-Tuning Vision Encoder): 這是 OpenVLA 的一項重要發現。與先前 VLM 工作傾向於凍結視覺編碼器不同,研究發現,在 VLA 訓練過程中微調視覺編碼器對於獲得良好的 VLA 性能至關重要。研究假設預訓練的視覺骨幹可能沒有捕捉到足夠精細的空間細節來實現精確的機器人控制。
- 優化動作編碼: OpenVLA 將連續的機器人動作離散化為 256 個 bin,並將其映射到 Llama tokenizer 詞彙表中最後 256 個最少使用的標記上。此外,它使用分位數 (quantiles) 而非極值來設定 bin 寬度,這有助於忽略數據中的離群動作,從而提高動作離散化的有效粒度。
- 大規模數據和清理: 論文策劃了一個比先前最先進模型 RT-2-X 更大的訓練數據集 (970k vs. 350k),並進行了更細心的數據清理,例如過濾掉 Bridge 資料集中的全零動作,這有助於緩解策略中出現的「冷凍行為」。
- 2. 計算效率與可近用性優化(加速普及)
- 參數高效微調 (PEFT): OpenVLA 深入探討了微調方法,並證明了使用 LoRA(低秩適應)技術,僅需更新模型中 1.4% 的參數,就能達到與完全微調相當的性能。這使得 OpenVLA 可以在單張消費級 GPU 上進行微調,大大降低了計算要求。
- 記憶體高效推理(量化): OpenVLA 是第一個證明現代量化 (quantization) 方法對 VLA 有效性的模型。透過使用 4 位元量化 (int4),OpenVLA 在推理時的 GPU 記憶體佔用可以減少一半以上(降至 7.0 GB),同時仍能匹配標準性能。
- 這些優化,特別是架構和訓練程序上的改進,使得 OpenVLA 能夠以 7 倍更少的參數 (7B vs. 55B) 在通用機器人操作中超越閉源模型 RT-2-X
- 核心算法
- 實驗效果
- 實驗一:多機器人平台的直接評估 (Direct Evaluations on Multiple Robot Platforms)
- 測試 OpenVLA 作為一個強大的多機器人控制策略的開箱即用 (out-of-the-box) 性能
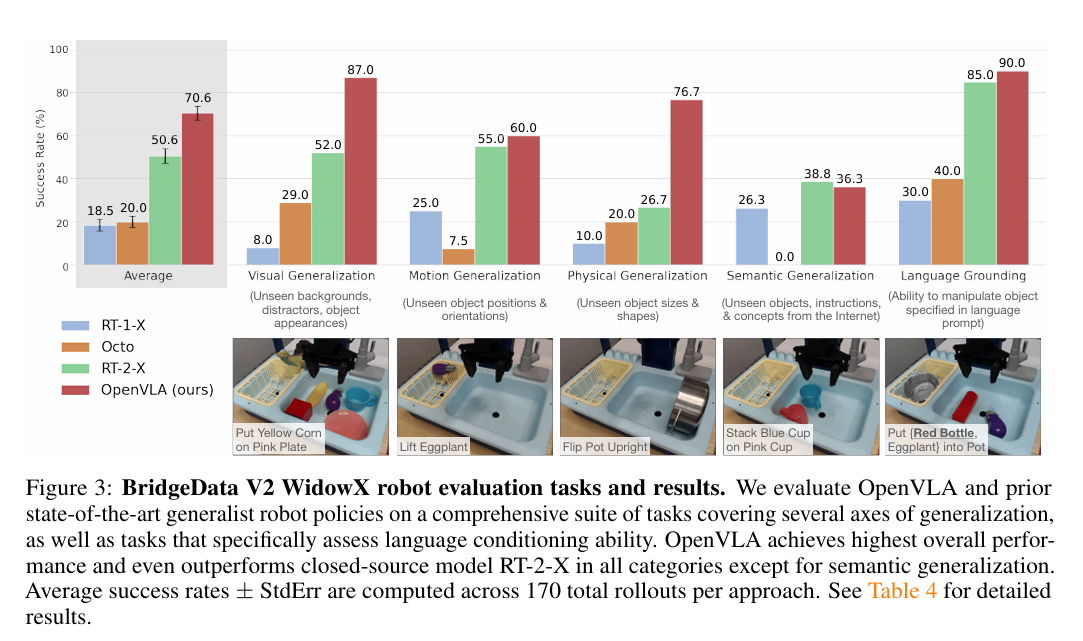
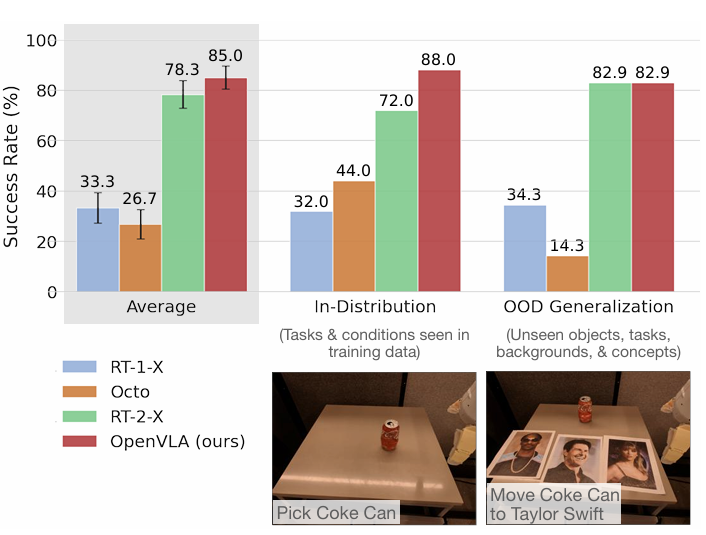
- 評估平台: 在兩種機器人實體上進行:WidowX 機器人 (BridgeData V2 評估) 和 Google 機器人 (RT-1 和 RT-2 評估中的移動操作機器人)。
- 泛化性評估:評估涵蓋多種泛化軸線,包括視覺、運動、物理、語義泛化,以及在多物體場景中的語言基礎能力。
- 主要成果: 儘管 OpenVLA 參數規模小了一個數量級 (7B 對 55B),但它在 BridgeData V2 評估中超越了閉源的 RT-2-X,絕對任務成功率高出 16.5%。在 Google 機器人評估中,OpenVLA 性能與 RT-2-X 相當。
- 性能解釋: OpenVLA 性能提升歸因於策劃了更大的訓練數據集 (970k 對 350k)、更仔細的數據清理(如過濾 Bridge 數據集中的全零動作),以及使用融合視覺編碼器。
- 實驗二:數據高效適應新機器人設置 (Data-Efficient Adaptation to New Robot Setups)
- 探究 OpenVLA 高效微調 (fine-tuning) 以適應新任務和機器人設置的能力,這是先前工作未深入探索的關鍵組成部分。
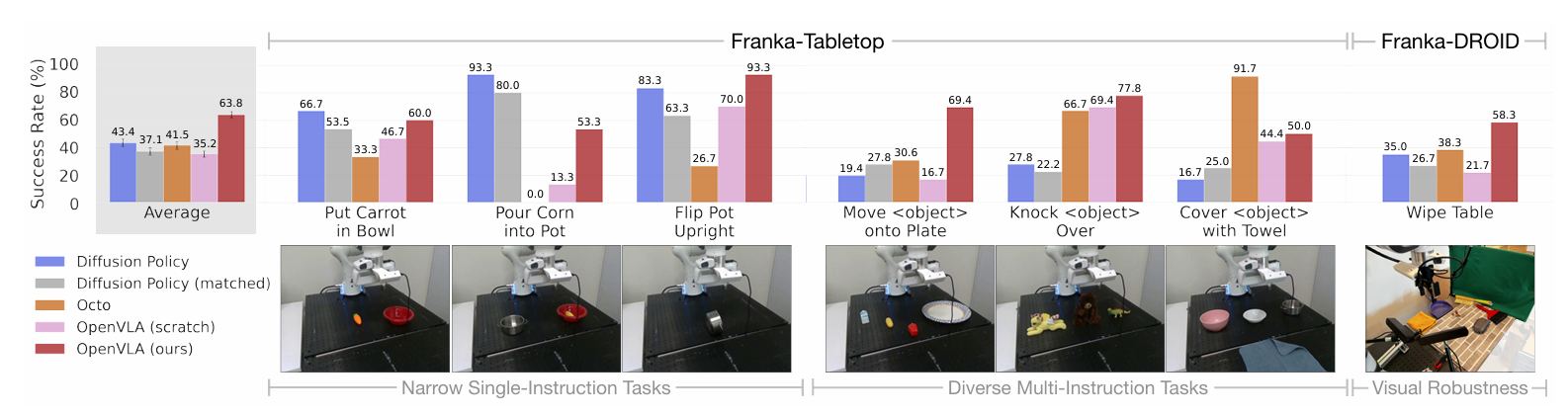
- 評估設置: 在兩種 Franka Emika Panda 機械手臂設置上進行全參數微調:Franka-Tabletop (5Hz 控制) 和 Franka-DROID (15Hz 控制)。微調使用了 10–150 個示範的小型數據集。
- 任務類型對比: 任務分為狹窄單指令任務和涉及多物體的多指令任務。
- 比較對象: 與從頭開始訓練的 Diffusion Policy (及其匹配版本) 和經過微調的 Octo 進行比較。同時使用 OpenVLA (scratch) 評估大規模預訓練的益處。
- 主要成果: OpenVLA 達到了最高的總體平均性能。OpenVLA 和 Octo 在涉及多物體和語言基礎的多指令任務中表現優於 Diffusion Policy。OpenVLA (scratch) 性能較低,證明 OpenX 預訓練對於適應多樣化任務是必需的。
- 實驗三:參數高效微調 (Parameter-Efficient Fine-Tuning, PEFT)
- 目標: 測試各種 PEFT 策略的有效性,以降低 OpenVLA 訓練時的計算需求和記憶體消耗。
- 比較策略: 比較了 Full FT、Last Layer Only、Frozen Vision、Sandwich Fine-tuning,以及不同等級的 LoRA (Low-Rank Adaptation)。
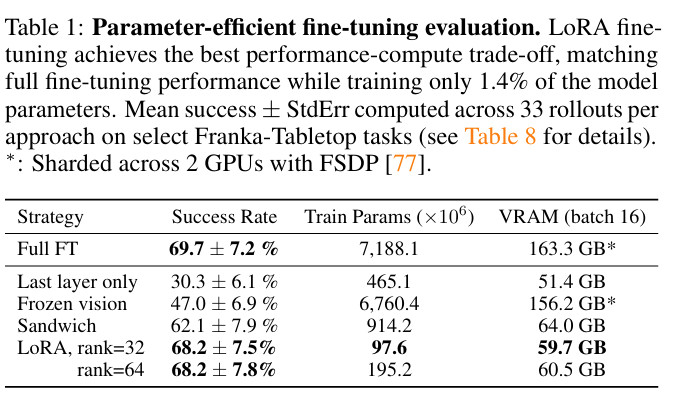
- 主要成果: LoRA (r=32) 實現了性能與訓練記憶體消耗的最佳權衡。LoRA 僅微調了模型中 1.4% 的參數 (97.6M),但成功率幾乎與完全微調 相當 (68.2% vs. 69.7%)。
- 重要發現: 僅微調最後一層或凍結視覺編碼器會導致性能不佳,表明視覺特徵需要進一步適應目標場景。
- 實驗四:透過量化實現記憶體高效推論 (Memory-Efficient Inference via Quantization)
- 測試使用現代量化技術在不損害成功率的情況下,減少 OpenVLA 模型推論時所需的 GPU 記憶體。
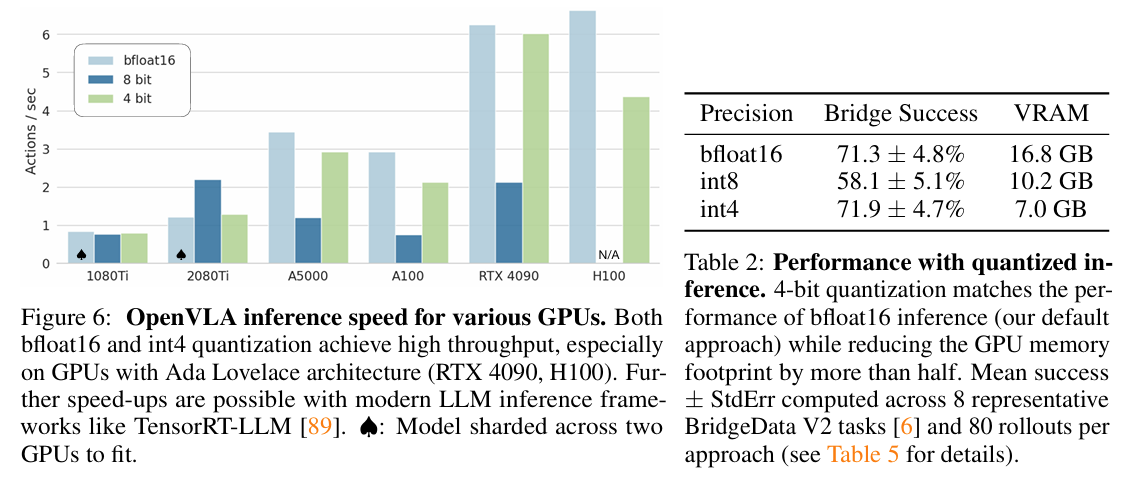
- 比較精度: 比較了 bfloat16 (預設半精度)、8-bit (int8) 量化 和 4-bit (int4) 量化。
- 主要成果: 4 位元量化 (int4) 在成功率上與 bfloat16 相當(71.9% vs. 71.3%),但將 GPU 記憶體佔用減少了一半以上(從 16.8 GB 降至 7.0 GB)。
- 速度問題: 8 位元量化性能顯著下降,經推測是由於推論速度較慢 (1.2Hz),與訓練數據集使用的 5Hz 非阻斷控制器系統動態不匹配。
- 實驗一:多機器人平台的直接評估 (Direct Evaluations on Multiple Robot Platforms)
- 優缺點分析
- 優點探討 (Advantages)
- OpenVLA 的主要優勢在於其開源精神、卓越性能以及對計算效率的深度探索,這些特性共同促進了 VLA 策略的廣泛採用。
- 1. 開源與可近用性 (Openness and Accessibility)
- 填補市場空缺:OpenVLA 是第一個 7B 參數的開源 VLA 模型。它旨在解決現有 VLA 模型(如 RT-2-X)大多是閉源且公眾難以取得的問題。
- 支持未來研究:論文釋出了模型檢查點、微調筆記本和 PyTorch 程式碼,為未來對 VLA 訓練、數據混合、目標和推論的研究提供了豐富的基礎。
- 高效部署:OpenVLA 可以透過現代低秩適應技術(如 LoRA)在消費級 GPU 上進行微調。這是先前工作未曾探索的新貢獻。
- 2. 卓越的性能與泛化能力 (State-of-the-Art Performance)
- 創下新技術水準:OpenVLA 為通用機器人操作策略建立了新的技術水準。
- 超越閉源模型:儘管 OpenVLA 的參數規模小了一個數量級(7B 對 55B),但其總體性能優於閉源模型 RT-2-X,在 29 項任務和多種機器人實體上的絕對任務成功率高出 16.5%。
- 穩健性和語言基礎:OpenVLA 展現出明顯更穩健的行為,例如在存在干擾物時能接近正確的目標物體,並正確調整機器人的末端執行器。在涉及語言落地 (language grounding) 的多任務環境中,OpenVLA 表現出特別強的泛化能力,比從零開始的模仿學習方法(如 Diffusion Policy)高出 20.4%。
- 跨機器人控制:OpenVLA 經過訓練可以開箱即用支援控制多種機器人,並且可以透過參數高效微調快速適應新的機器人領域。
- 3. 計算效率與實用性 (Compute Efficiency and Practicality)
- 參數高效微調:論文首次展示了 LoRA 對 VLA 的有效性。LoRA 實現了性能與訓練記憶體消耗之間的最佳權衡,僅需更新模型中 1.4% 的參數即可匹配完全微調的性能。
- 高效推理:OpenVLA 是第一個證明 4 位元量化 (int4) 技術對 VLA 有效性的模型。該技術可以在不損害下游任務成功率的情況下,將 GPU 推論記憶體佔用減少一半以上(從 16.8 GB 降至 7.0 GB)。
- 缺點與限制探討 (Disadvantages and Limitations)
- 儘管 OpenVLA 具有許多優勢,論文也坦誠地指出了該模型及當前 VLA 技術的幾個限制:
- 1. 感官輸入的限制 (Sensory Input Limitations)
- 單一圖像輸入:OpenVLA 目前只支持單一圖像觀察。
- 異構輸入缺失:現實世界中的機器人設置是異構的,通常需要處理多個圖像輸入、本體感覺輸入以及觀察歷史。擴展 OpenVLA 以支援這些輸入是未來重要的研究方向。
- 2. 性能與推論速度的瓶頸 (Performance and Inference Speed Bottlenecks)
- 可靠性不足:雖然 OpenVLA 超越了先前的通用策略,但其在測試任務上的可靠性尚未達到非常高,通常成功率低於 90%。
- 精細靈巧性:對於某些狹窄但要求高度靈巧的任務,從零開始訓練的 Diffusion Policy 仍能展現更平滑和更精確的軌跡。
- 推論速度需求:OpenVLA 的推論吞吐量 (inference throughput) 仍需提高,以支援 ALOHA 等 50Hz 的高頻率控制設置。
- 量化影響:實驗顯示,由於 8 位元量化會導致推論速度過慢 (1.2Hz),這顯著改變了系統動力學,從而在非阻斷控制下導致性能大幅下降。
- 3. 計算限制導致的未探索設計問題 (Underexplored Design Questions)
- 由於計算資源的限制,許多 VLA 設計的核心問題仍未得到深入探討,這些是 OpenVLA 論文本身無法完全解決的限制:
- ◦ 基礎 VLM 的規模(例如 Llama 2 7B)對於 VLA 性能的影響為何?
- ◦ 共同訓練機器人動作預測數據和網際網路規模的視覺-語言數據(如 RT-2-X 所採用)是否會實質性地改善 VLA 性能?
- ◦ 哪種視覺特徵最適合用於 VLA 模型?
- 由於計算資源的限制,許多 VLA 設計的核心問題仍未得到深入探討,這些是 OpenVLA 論文本身無法完全解決的限制:
- 總結來說,OpenVLA 的優勢在於其開創性的開放性、卓越的通用性能以及對計算資源的高效利用,使先進的 VLA 技術得以普及。而其主要限制則圍繞在感官輸入的單一性以及在極高頻率控制和極高可靠性任務上的性能瓶頸。
- 優點探討 (Advantages)
OpenVLA: AnOpen-Source Vision-Language-Action Model
Subscribe
Login
0 Comments
Oldest